
Optimization in Deep Learning
최적화와 관련된 주요한 용어와 내용(Generalization, Overfitting, Cross-validation) 그리고 기존 SGD(Stochastic gradient descent)를 넘어서 최적화(학습)가 더 잘될 수 있도록 하는 다양한 기법들에 대해 알아봅니다.
Important Concepts in Optimization
- Generalization
- Under-fitting vs. over-fitting
- Cross validation
- Bias-variance
- Bootstrapping
- Bagging and boosting
Generalization
일반화는 학습 데이터로 학습이 되어진 모델이 얼마나 테스트 데이터에서 잘 동작하는지(문제에 따라 에러를 최소화)를 나타내는 개념입니다.
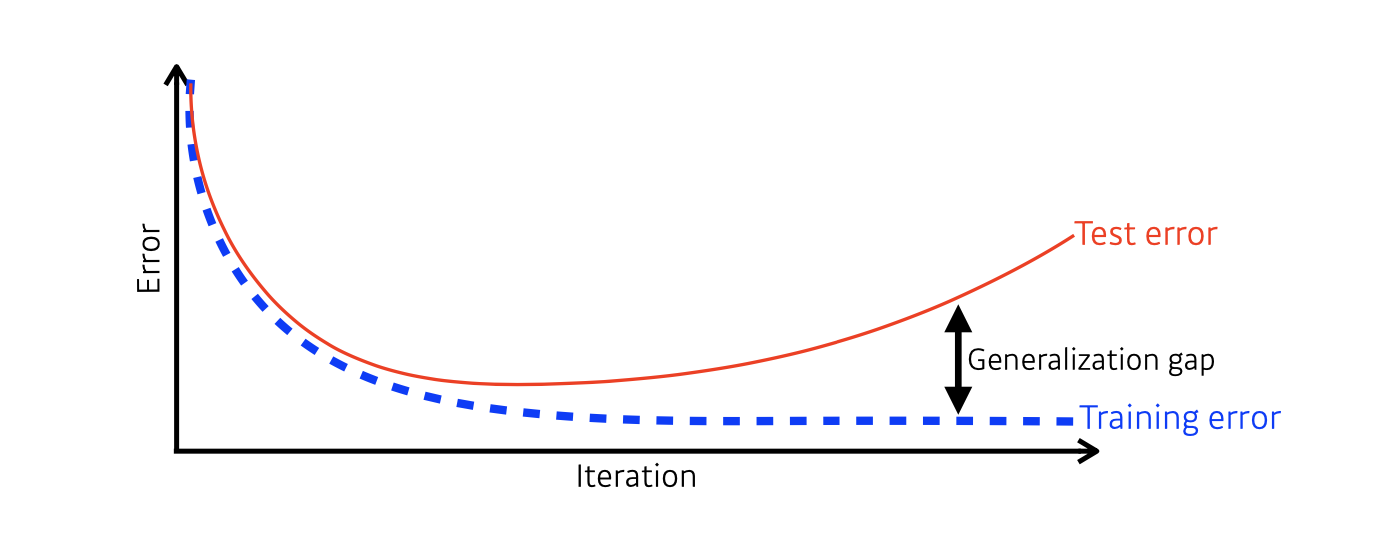
위의 그림처럼 학습 데이터를 반복적으로 학습함에 따라 모델은 Training Error는 줄어들게 됩니다.
그렇다고 Training Error가 최소값이 되었다고 해서 우리의 모델이 최적화 되었다고 할 수는 없습니다.
일반적으로 Training Error가 줄어들지만, 어느정도 반복 학습이 이루어지고 시간이 지나면 학습하지 않은(한번도 보지 않은) 테스트 데이터에 대해서는 Test Error가 올라가게 됩니다.
Generalization Gap은 Training Error와 Test Error 사이의 차이를 의미합니다.
그래서 Training Error와 Test Error의 차이 즉, Generalization Gap이 작을 때 우리는 Generalization Performance가 좋다고 말할 수 있고, Generalization Gap이 클 때 Generalization Performance가 좋지 않다고 말 할 수 있습니다.
주의할 점은 Test Error가 낮다고 해서 Generalization Performance 좋은 것이 아닙니다.
Generalization Performance는 단지 두 Error의 차이에 따른 성능만을 의미하는 것이기 때문입니다.
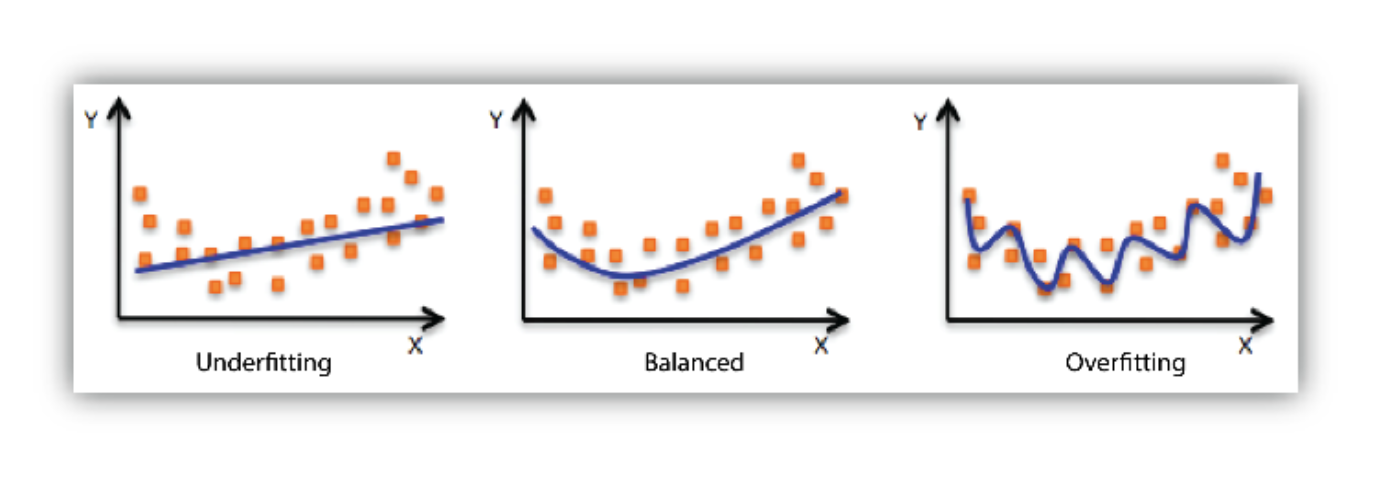
Underfitting vs. Overfitting
Overfitting은 학습데이터에 대해서는 잘 동작 하지만 테스트 데이터에 대해서는 잘 동작하지 않는 현상을 의미합니다. 이는 모델이 학습 데이터에 대해 너무 과적합하게 학습된 나머지, 한 번도 보지 못한 테스트 데이터에 대해서는 잘 동작하지 않는 것을 의미하게 됩니다.
Underfitting은 네트워크가 너무 간단하거나 학습을 너무 조금 시켜서 학습 데이터 마저도 잘 맞추지 못하는 현상을 의미하게 됩니다.
밑의 그림에서 볼 수 있듯이 학습데이터에 대해 너무 과적합하지 않으면서도 간단하거나 부족하지 않은 중간의 모델이 Balance하다고 할 수 있습니다.
하지만 문제에 따라서는 오른쪽 그림과 같이 파란 선들이 Target일 수도 있어서 이 개념들은 컨셉적인 이야기라고 보면 될 것 같습니다.
Cross-validation
전체 데이터를 크게 학습 데이터와 테스트 데이터로 나누는데, 학습 데이터에서 일정 부분을 검증을 위해 때어내서 만든 데이터를 Validation Data 라고 합니다.
Validation Data를 만들어 사용하는 이유는 학습 데이터로 학습을 시킨 모델이 학습에 사용되지 않은 Validation Data 기준으로 얼마나 잘 동작하는지 알아보기 위함입니다.
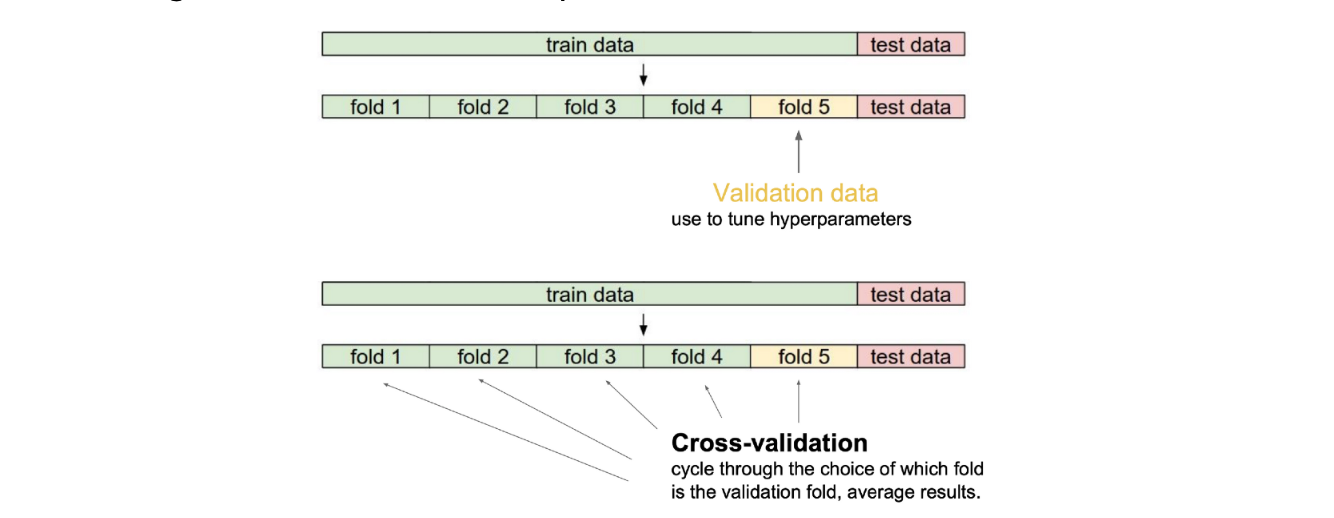
K-fold Validation이라고도 불리는 Cross validation은 학습 데이터를 k개의 fold로 나누고, 1개의 fold는 검증에 사용할 validation data로, 나머지 k-1개의 fold는 학습 데이터로 사용하는 것입니다.
이를 fold 마다 한번 씩 번갈아 가며 k번 수행하면 총 5개의 서로 다른 validation 값이 나오게 되고, 이 값들을 평균낸 값을 사용하게 됩니다.
모델을 학습 시키는데에 있어서 중요한 하이퍼 패러미터(Learning Late, 손실함수, 네트워크의 크기 등)를 정하기 위해 먼저 교차 검증을 수행하고 하이퍼 패러미터가 교정이 되면, 검증 데이터를 학습 데이터에 포함시켜 전체 학습 데이터에 대해 모델을 학습합니다. 이 때, 테스트 데이터를 사용해서 교차검증을 한다거나 하이퍼 패러매터를 설정하는 것 등… 무슨 이유에서건 테스트 데이터를 학습에 사용되서는 안됩니다.
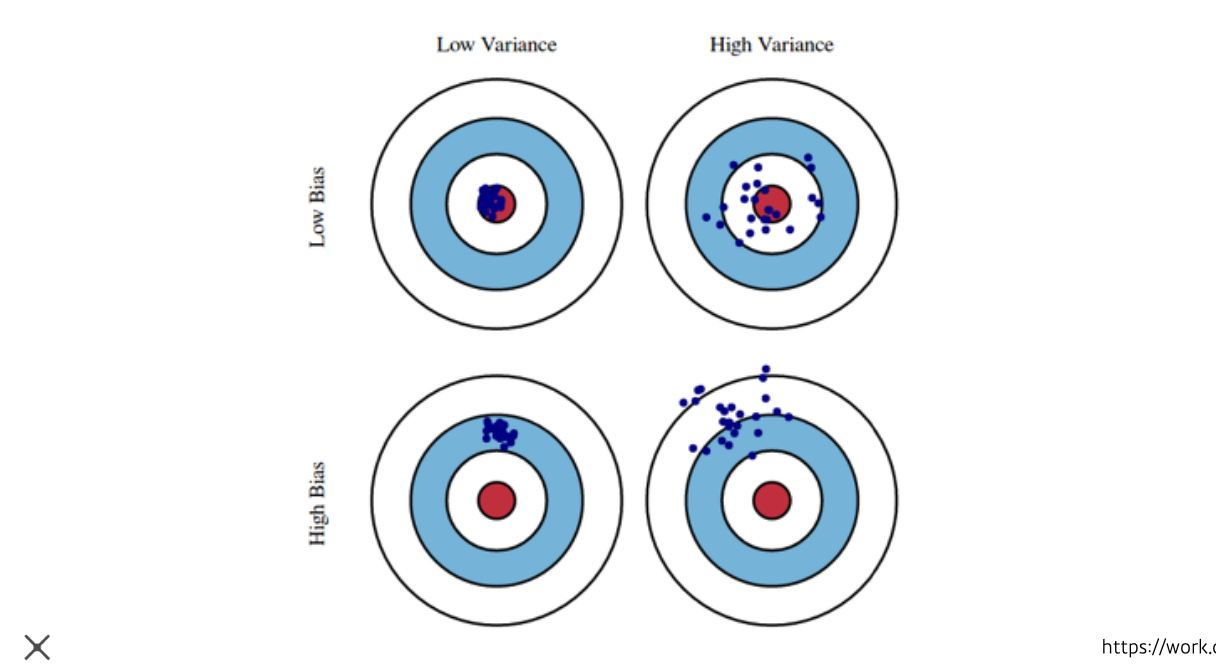
Bias and Variance
- Low Variance는 비슷한 입력을 넣었을 때, 얼마나 일관된 출력을 내는지를 의미합니다. 이는 주로 모델이 간단할 때 나타나는 현상입니다.
- High Variance는 비슷한 입력을 넣었을 때, 출력이 많이 달라지게 되는 것을 의미합니다. 이렇게 되면 모델이 Overfitting 될 가능성이 커지게 됩니다.
- Low Bias는 전체적인 출력 값이 Target 또는 Mean과 가깝다는 것을 의미합니다.
-
High Bias는 전체적인 출력 값이 Target 또는 Mean과 다소 떨어져 있다는 것을 의미합니다.
Bootstrapping
고정된 수의 학습데이터에 대해 랜덤하게 샘플링 된 데이터로 여러 모델을 만들어 어떤 목적을 수행하겠다는 방법론을 말합니다.
예를 들어 전체 데이터의 수가 100개이면 그 중 랜덤하게 80개를 뽑아 모델 1을 학습시키고, 다시 랜덤하게 80개를 뽑아 모델 2를 학습시키고… 이렇게 수행하게 됩니다.
이렇게 되면 하나의 입력에 대해서 여러개의 모델이 같은 값을 예측할 수도 있지만 서로 다른 값을 예측할 수도 있습니다.
그래서 입력 값들에 대해 이 모델들의 출력 값이 얼마나 일치하는 지를 보고 전체적인 모델의 Uncertainty를 예측하고자 할 때 사용할 수 있습니다.
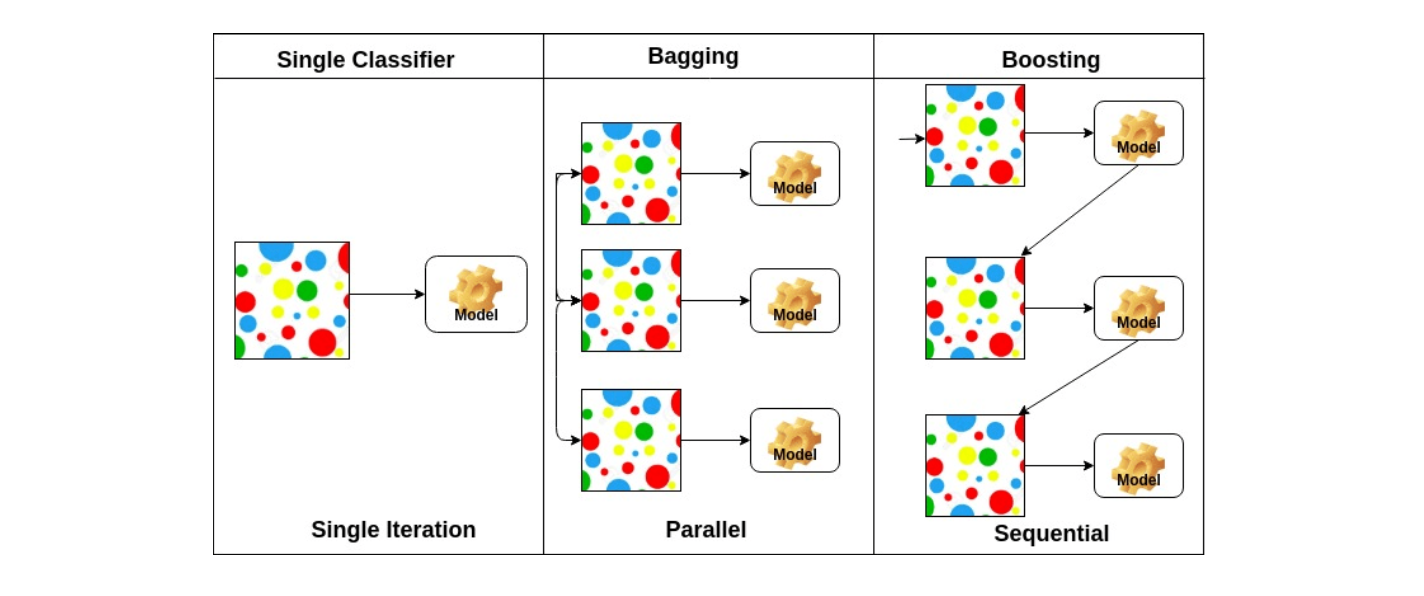
Bagging vs Boosting

Bagging : 위에서 다룬 Bootstrapping 방법을 쓰는 데, 전체 데이터에서 일부를 랜덤 샘플링 해서 여러 개의 모델을 만들고, 그 모델들의 아웃풋을 가지고 평균을 내는 것을 의미하게 됩니다. 이런 것을 일반적으로 앙상블이라고도 부릅니다.
Boosting : 전체적인 프로세스가 Sequential 하게 전체 학습 데이터에 대해 모델을 만들고 그 중 학습이 잘 안된 데이터에 대해 또 다른 모델을 만들어 이 학습이 잘 안된 데이터에 대해 학습이 잘 되도록 모델을 만드는 것을 반복합니다. 그리고 이렇게 만든 모델들을 Sequential하게 합쳐 하나의 모델을 만듭니다.
Gradient Descent Methods
Gradient Descent 분류해보면 크게 3가지로 분류해 볼 수 있습니다.
- Stochastic gradient descent : 엄밀하게 얘기해서 전체 학습 데이터에서 한번에 한개의 샘플 데이터에 대해서 역전파를 통해 그레디언트를 구하고, 값을 업데이트하고, 다시 한번에 한개의 샘플 데이터에 대해 반복하는 것을 말합니다.
- Mini-batch gradient descent : 배치 사이즈인 256개나 128개 등의 학습 데이터의 서브셋에 대해 계산된 그레디언트를 업데이트 하는 방법을 말합니다.
- Batch gradient descent : 전체 데이터에 대해 계산된 그레디언트를 사용해 패러매터를 업데이트 하게 되는 것을 말합니다.
대부분의 딥러닝 문제에서는 Mini-batch gradient descent가 사용되어지고 있습니다.
Batch-size Matters
많은 딥러닝 문제에서 Batch-size는 아주 중요한 요소입니다.
Batch-size에 따라 우리가 추구하고자 하는 모델이 이상적으로 가는지, 잘 학습이 되어지는에 대해 결정적일 수 있기 때문입니다.

실험적으로 발견이 되어진 내용에 의하면 큰 Batch-size를 사용하여 모델을 학습하게 되면, 학습과 테스트 함수가 sharp minimizers에 도달할 가능성이 크다고 합니다. 반면에 작은 Batch-size를 사용하게 되면 flat minimizers에 도달할 가능성이 크다고 합니다.
여기서 말하고자 하는 내용은 Batch-size를 작게쓰는 것이 일반적으로 성능이 좋다라는 것을 실험적으로 말하는 것입니다.
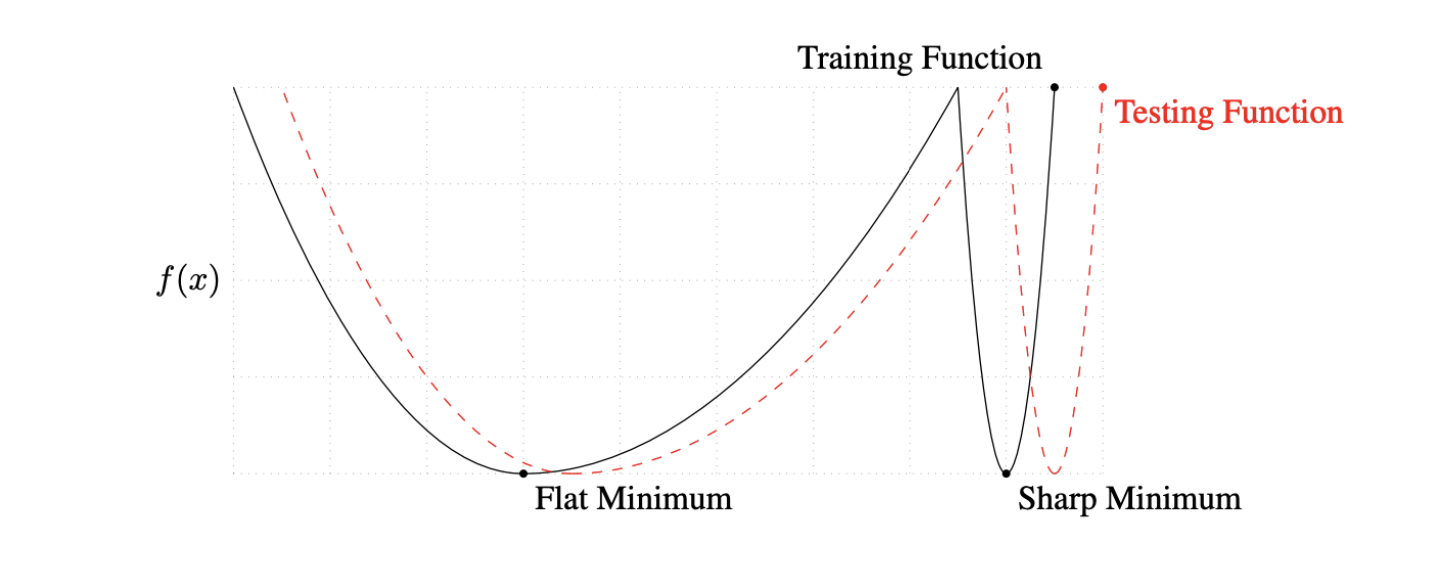
우리의 목적은 데이터가 Testing function에서 잘 동작하는 것을 찾고 싶습니다.
Flat minimum에서 Training Function 값이 조금 멀어져도, Testing Function에서도 적당히 비슷한 값이 나오는 것을 볼 수 있습니다. 이 말은 학습 데이터에서 잘 동작하는 것이 테스트 데이터에서도 잘 동작하는 즉, 앞에서 살펴본 Generalization performance가 높다고 할 수 있습니다.
Sharp minimum 에서는 Training Function에서 Local minimum에 도달했어도 Testing Function에서는 약간만 멀어져 있어도 높은 값이 나오는 것을 볼 수 있습니다. 이 말은 학습 데이터에서 잘 동작하는 것이 테스트 데이터에서는 잘 동작하지 않는 또는 예측하지 않는 즉, Generalization performance가 낮다고 할 수 있습니다.
Gradient Descent Methods
- Stochastic gradient descent
- Momentum
- Nesterov accelerated gradient
- Adagrad
- Adadelta
- RMSprop
- Adam
Gradient Descent
가장 일반적인 Gradient Descent 방법입니다.

W는 업데이트 될 패러미터 백터, t는 타임스탬프, g는 자동미분으로 얻어진 그레디언트를 의미합니다.
그레디언트 값을 에타라고도 부르는 Learning rate 값과 곱해서 W와 빼주고 그 값을 새로 업데이트 하게 되는 방법입니다.
이 방법의 가장 큰 문제는 스텝 사이즈인 Learning rate를 정하는 것이 너무 어렵다는 점입니다.
Learning rate가 너무 크게 되면 학습이 잘 안되게 되고, 이 것이 너무 작으면 아무리 학습을 시켜도 학습이 안되게 될 것입니다.
그래서 이 Learning rate를 적절히 잡아주는게 중요합니다.
Momentum
관성이라고도 하는 이 방법은 쉽게 말해 한 번 그레디언트 방향이 a방향으로 흘렀다면, 다음번에 업데이트에서 계산된 그레이언트가 조금 다른 방향으로 흘러도 전에 흐르던 방향인 a방향의 정보를 조금 추가해서 그 방향을 보정하거나 이어가자는 것을 의미합니다.

베타상수가 모멘텀이 되고 a_t+1이 accumulation이 됩니다.
즉 한 번 계산되고 나서 g_t가 버려지게 되는 것이 아니고, 이 값이 베타 상수인 모멘텀과 같이 계산되어 accumuaation에 들어가게 되고 현재 뿐만 아니라, 다음 번의 경사하강 업데이트 계산에 a_t로서 계산이 들어가게 됩니다.
미니 배치 연산에서 에를 들면 전의 배치에서는 경사가 이쪽 방향으로 흘렀지만 다음 번 배치에서는 다른 방향으로 흐를 수 있고 이 때, 전에 계산된 방향으로 조금 보정해서 또는 관성을 줘서 흘러가자라는 것을 볼 수 있습니다.
그래서 그레디언트가 아주 많이 다 방향으로 왔다갔다 해도 어느정도 잘 학습이 되게 만들어 주는 효과가 있다고 합니다.
Nesterov Accelerated Gradient
NAG라고 불리는 이 경사하강 방법도 위에서 살펴본 Momentum과 비슷한 모양을 띄고 있습니다.
컨셉적으로 a라는 Accumulate gradient가 Learning rate와 곱해져서 Gradient Descent를 하게 되는 것인데, 위에 것과 조금 다른 점이라면 위에서 살펴본 g_t gradient를 계산 할 때 Lookahead gradient를 계산하게 됩니다.
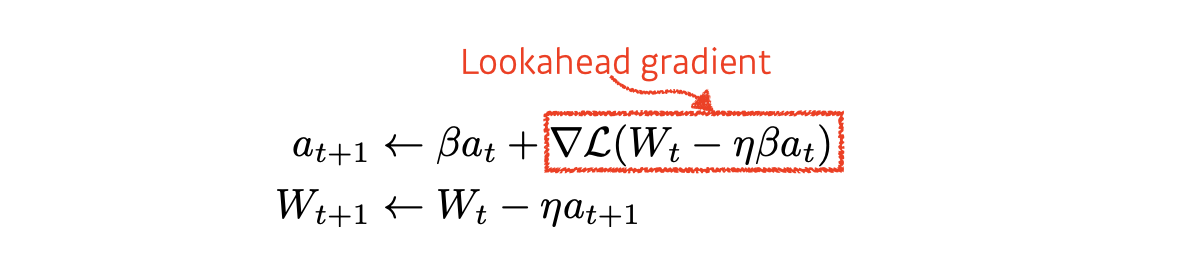
Lookahead gradient는 a라고 불리는 현재 gradient 정보가 있으면, 그 방향으로 한 번 가보고, 간 곳에서 다시 gradient를 계산에 accumulate 시켜주게 됩니다.
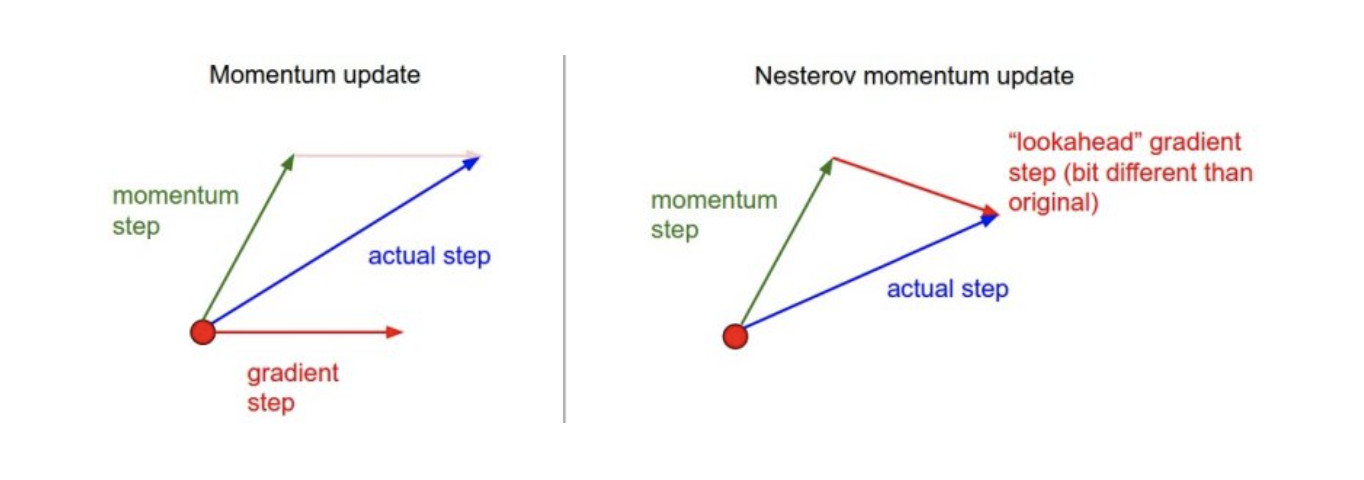
Nesterov Accelerated Gradient 방법은 Momentum에 비해 local minima에 조금 더 빨리 converge 할 수 있다고 할 수 있습니다.
Adagrad
이 방법은 뉴럴 네트워크가 학습하면서 시간적으로 얼마나 패러미터가 변해왔는지 안 변해 왔는지를 보게 되고, 값이 많이 변한 패러미터들에 대해서는 다음번에 더 적게 변화 시키고, 반대로 값이 적게 변한 패러미터들에 대해서는 다음번에 더 크게 변화 시키게 됩니다.
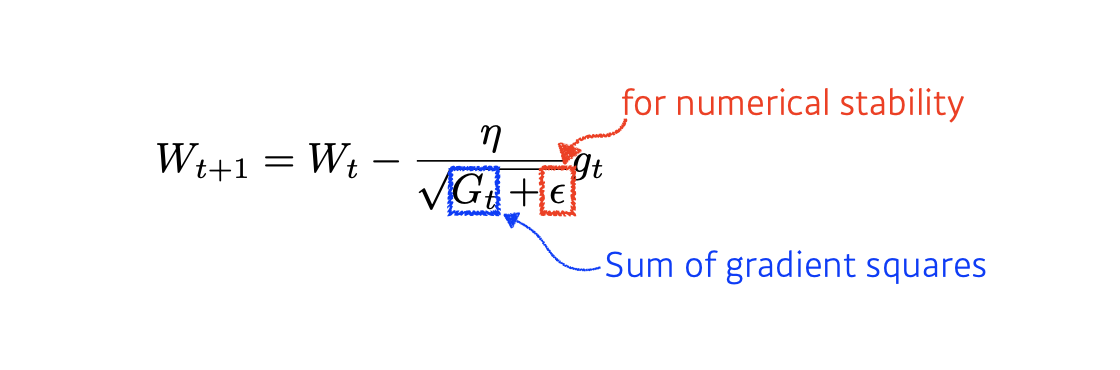
G_t는 학습하면서 지금까지 얼머나 gradient가 변했는지를 제곱해서 더한 값입니다.
이 값이 커진다는 것은 그 해당하는 패러미터들이 많이 변했다는 것을 의미하고, 이 값을 역수를 취해 넣었기 때문에, 다음번의 경사 하강에서는 그 해당하는 패러미터들이 보다 적은 배율로 업데이트가 이루어 집니다.
위의 룰을 적용해, G_t값이 작을 때는 다음번에 좀 더 많이 패러미터들을 변화시키겠다는 말이 됩니다.
입실론 상수는 learning rate가 0으로 나눠지는 것을 방지하기 위한 (forNumerical stability) 값이 됩니다.
Adagrad에서 식에서도 유추해볼 수 있는 가장 큰 문제라면, G_t값이 무한대로 계속 커지게 된다면 분모가 무한대이므로 W_t의 왼쪽에서 계산된 텀인 gradient 값은 무한대로 작아지고 결국, W의 업데이트가 이루어지지 않을 것입니다. 그래서 학습이 진행되면서 뒤로 가면 갈 수록 학습이 멈춰지는 현상이 생긴다는 것입니다.
Adadelta
이 방법은 위에서 살펴본 Adagrad에서 G_t 값이 무한대로 커지는 현상을 방지하는 것을 추가한 방법이라고 보면 됩니다.
Adadelta는 이전의 모든 그래디언트를 누적하는 대신 그래디언트 업데이트의 이동 창을 기반으로 학습률을 조정하는 Adagrad 보다 강력한 확장론적 방법이라고 볼 수 있습니다.
이렇게 하면 Adadelta는 많은 업데이트가 수행 된 경우에도 계속해서 학습할 수 있습니다.

EMA : Exponential Moving Average
H_t는 내가 실제로 업데이트 하고하자는 패러미터의 값을 미분하여 제곱한 값이 되고 이를 H_t-1의 값과 감마 상수를 잘 조합한 값이 됩니다.
이를 위에서 본 G_t값에 대한 역수로 넣어주게 됨으로써 학습이 진행됨에 따라 뒤로가도 학습이 계속 진행되도록 할 수 있습니다.
RMSprop
Adadelta에서 살펴본 H_t값과 입실론의 루트 값 대신에 Learning rate텀이 대신 들어간 방법이 됩니다.
위에서 처럼 G_t를 그냥 쓰는것이 아닌, EMA의 값을 취해서 분모로 취해주게 됩니다.
분자에는 에타라는 Learning rate가 들어가게 됩니다.
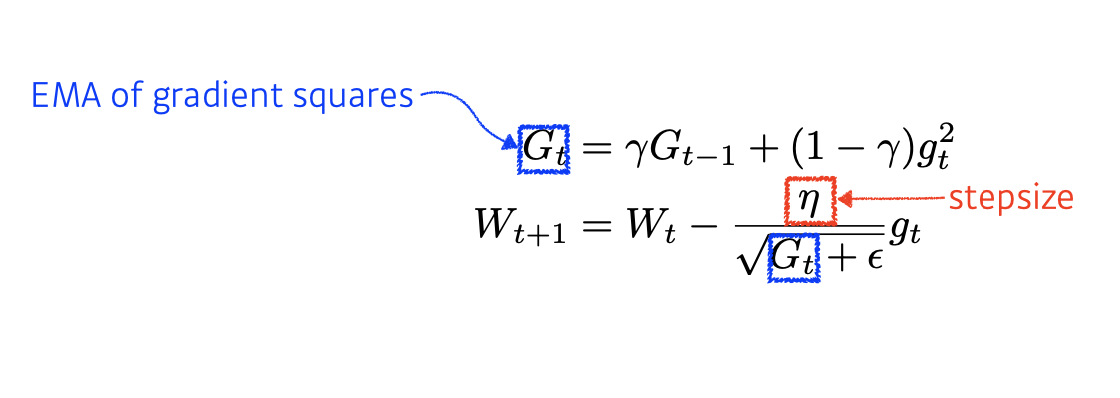
Adam
일반적으로 Gradient descent 최적화 방법론 중 가장 잘 되고 무난하게 사용되는 것이 이 방법입니다.
Gradient squares를 Exponential Moving average로 가져감과 동시에 앞에서 보았던 모멘텀을 같이 활용하는 방법이 됩니다.
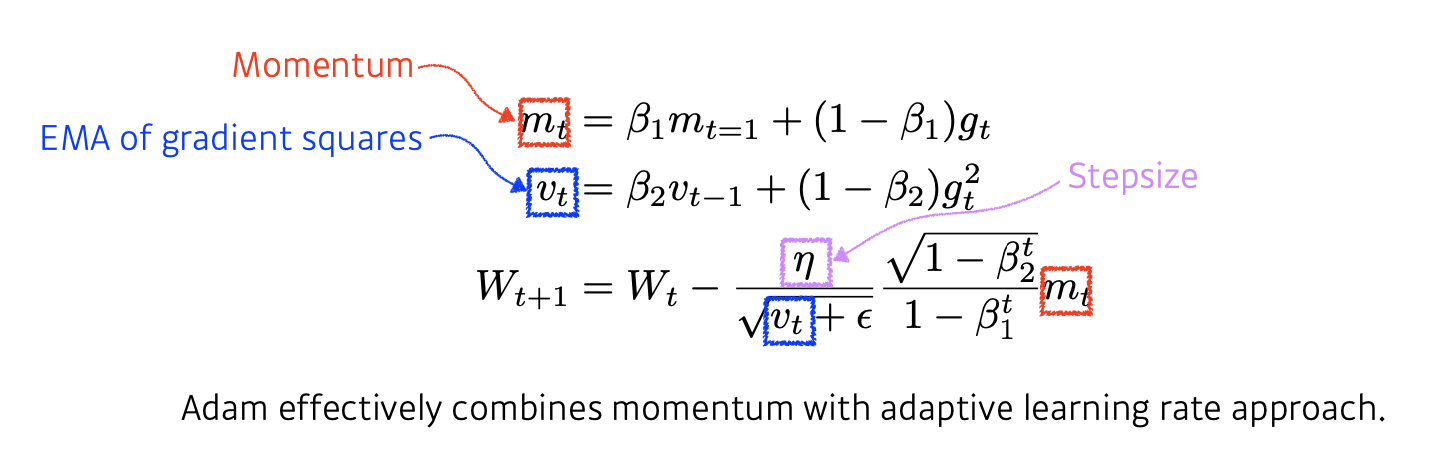
그레디언트의 크기가 바뀜에 따라 혹은 그레디언트 제곱의 크기에 따라서 적응적으로 Learning rate를 바꾸는 것과 이전에 계산된 모멘텀을 현재 그레디언트 값과 조합해 새로운 모멘텀을 조합하는 방법을 말하고 있습니다.
즉, Adam은 momentum과 adaptive Learning rate approach를 조합한 방법이 됩니다.
Hyperparameter는 베타1(모멘텀을 얼마나 유지시킬지), 베타2(Gradient square에 대한 EMA 정보), 에타(Learning rate), 입실론(for numerical stability)가 있습니다.
m_t옆에 root(1-b_2) / 1-beta_1 라는 것이 있는데, 이 전체 방법론이 Unbiased estimater가 되기 위해서 수학적으로 정의된 텀입니다.
딥러닝 프레임워크에서 입실론 패러미터가 기본적으로 약 10의 -7 제곱의 값으로 되어 있는데, 이 값을 잘 조정해주는 것이 Practical한 상황에서는 중요하다고 합니다.
References
- Optimization in Deep Learning - 최성준 교수님
Leave a comment