
Intro to NLP, Bag-of-Words, Naive Bayes Classifier
NLP에 대해 짧게 소개하고 자연어를 처리하는 가장 간단한 모델 중 하나인 Bag-of-Words를 알아봅니다.
Bag-of-Words는 단어의 표현에 있어서 one-hot-encoding을 이용하며, 단어의 등장 순서를 고려하지 않는 아주 간단한 방법 중 하나입니다. 간단한 모델이지만 많은 자연어 처리 task에서 효과적으로 동작하는 알고리즘 중 하나입니다.
그리고, 이 Bag-of-Words를 이용해 문서를 분류하는 Naive Bayes Classifier에 대해서 설명합니다.
What is Natural language processing? (NLP)
Natural language processing (NLP), which aims at properly understanding and generating human languages, emerges as a crucial application of artificial intelligence, with the advancements of deep neural networks.
인간의 언어를 적절하게 이해하고 생성하는 것을 목표로하는 자연어 처리 (NLP)는 심층 신경망의 발전과 함께 인공 지능의 중요한 응용 프로그램으로 부상하고 있습니다.
NLP is used in various field in deep learning approaches as well as their applications such as language modeling, machine translation, question answering, document classification, and dialog systems.
NLP는 언어 모델링, 기계 번역, 질문 답변, 문서 분류 및 대화 시스템과 같은 응용 프로그램뿐만 아니라 딥 러닝 접근 방식의 다양한 분야에서 사용됩니다.
Natural language processing의 연구동향은 ACL, EMNLP, NAACL와 같은 학회에서 발표가 됩니다.
Academic Disciplines related to NLP
Natural language processing (major conferences: ACL, EMNLP, NAACL)
-
Low-level parsing : Tokenization(문자를 특정 단위로 자르는 것), stemming(영어, 한글에서와 같이 같은 의미론적의 단어라도 어미나 형태가 달라질 수 있고, 여기서 어근을 뽑아내는 것 ex) study, studied, studying…)
-
Word and phrase level : Named entity recognition(NER), part-of-speech(POS) tagging, noun-phrase chunking, dependency parsing, coreference resolution
-
Sentence level : Sentiment analysis(감정 분석), machine translation(기계 독해)
-
Multi-sentence and paragraph level : Entailment prediction, question answering(질문에 대한 정확한 대답), dialog systems(챗봇), summarization(긴 문장이나 문단에 대해서 짧게 요약)
Text mining (major conferences: KDD, The WebConf (formerly, WWW), WSDM, CIKM, ICWSM)
-
Extract useful information and insights from text and document data : 예를 들어, 방대한 뉴스 데이터로 부터 현재 AI 트렌드 키워드를 분석하는 것
-
Document clustering (e.g., topic modeling) : 방대한 데이터로 부터 여러 다른 주제에 대해 서로 그룹화 하는 것
-
Highly related to computational social science : 예를 들어, 소셜 미디어 데이터에 기반해 사람들의 정치적 성향의 변화를 분석하는 것
Information retrieval (major conferences: SIGIR, WSDM, CIKM, RecSys)
- Recommendation system : 추천 시스템 (사용자의 성향을 바탕으로 관련된 토픽을 추천해 주는 등…)
Trends of NLP
Text data can basically be viewed as a sequence of words, and each word can be represented as a vector through a technique such as Word2Vec or GloVe.
RNN-family models (LSTMs and GRUs), which take the sequence of these vectors of words as input, are the main architecture of NLP tasks.
Overall performance of NLP tasks has been improved since attention modules and Transformer models, which replaced RNNs with self-attention, have been introduced a few years ago.
As is the case for Transformer models, most of the advanced NLP models have been originally developed for improving machine translation tasks.
In the early days, customized models for different NLP tasks had developed separately.
Since Transformer was introduced, huge models were released by stacking its basic module, self-attention, and these models are trained with large-sized datasets through language modeling tasks, one of the self-supervised training setting that does not require additional labels for a particular task.
Afterwards, above models were applied to other tasks through transfer learning, and they outperformed all other customized models in each task.
Currently, these models has now become essential part in numerous NLP tasks, so NLP research become difficult with limited GPU resources, since they are too large to train.
Bag-of-Words
Bag-of-Words는 단어의 표현에 있어서 숫자 형태로 나타내는 one-hot-encoding을 이용하며, 단어의 등장 순서를 고려하지 않는 아주 간단한 방법 중 하나입니다. 간단한 모델이지만 많은 자연어 처리 task에서 효과적으로 동작하는 알고리즘 중 하나입니다.
Step 1. Constructing the vocabulary containing unique words
문장들에서, 고유한 단어들을 뽑아서 단어사전을 구축합니다.

Step 2. Encoding unique words to one-hot vectors
고유한 단어들을 순서대로 원-핫-인코딩을 적용합니다.
항상 자기 자신을 제외한 어느 단어들과의 유클리드 거리는 루트 2, 코사인 유사도(내적)은 0이 됩니다.

Step 3. A sentence/document can be represented as the sum of one-hot vectors
sentence/document를 이뤘던 단어들의 원-핫 벡터를 Element wise하게 모두 더해줍니다.

NaiveBayes Classifier for Document Classification
Bag-of-Words로 나타내어진 문서를 정해진 카테고리 혹은 클래스로 분류할 수 있는 모델입니다.
- Bag-of-Words for Document Classification
Bayes’ Rule Applied to Documents and Classes
d = 분류 되어질 문서, C = C개의 클래스
특정한 문서 d가 주어져 있을 때, 그 문서가 특정 클래스 중 하나인 c에 속할 확률 : P(c|d), 조건부 확률 분포상, 가장 높은 확률을 가지는 c를 통해서 문서 분류를 수행
P(c|d)는 Bayes’ Rule에 의해 아래의 그림에서의 중간 식과 같이 나타내어 질 수 있다.
Bayes’ Rule에서 P(d)는 문서 d가 뽑힐 확률, d는 우리가 분류할 고정된 하나의 개체라고 볼 수 있으므로, argmax operation 상에서 상수로 무시할 수 있게 되고, 이는 맨 아래의 식으로 유도될 수 있음.

P(d|c)는 특정 클래스가 고정이 되었을 때, 문서 d가 나타날 확률을 의미. 문서 d가 나타날 확률은 문서에서의 단어 w1 .. wn가 동시적으로 그리고 독립적으로 일어난 사건을 의미.

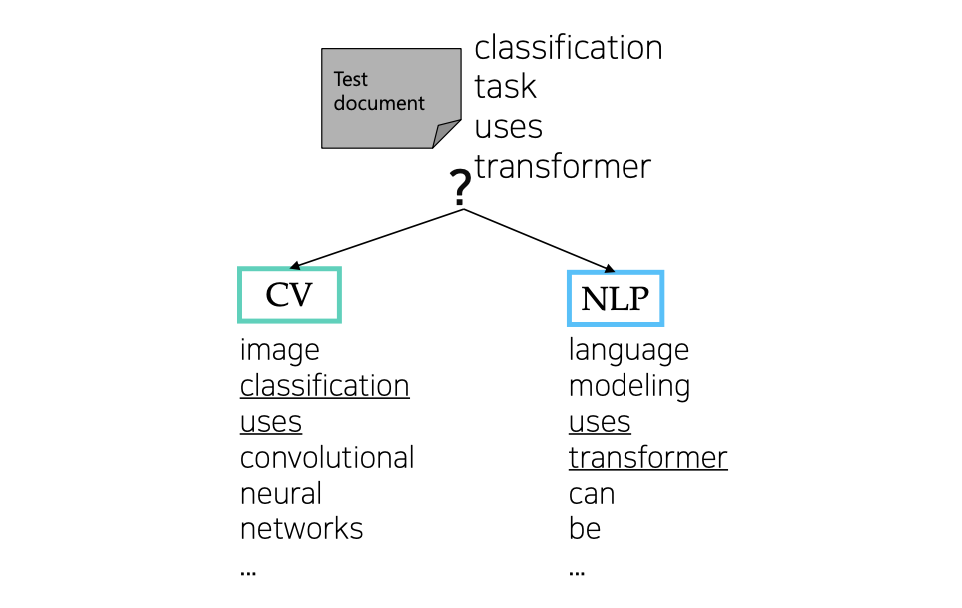
예시로, 다음과 같이 d가 4개, 그 다음 각 문서에서의 단어들 w, 그리고 문서들이 속할 클래스 c가 있습니다.
P(c_cv)는 문서 cv가 선택될 확률이므로 전체 4개의 문서 중 2개 : 0.5
P(c_NLP)도 위와 같습니다.

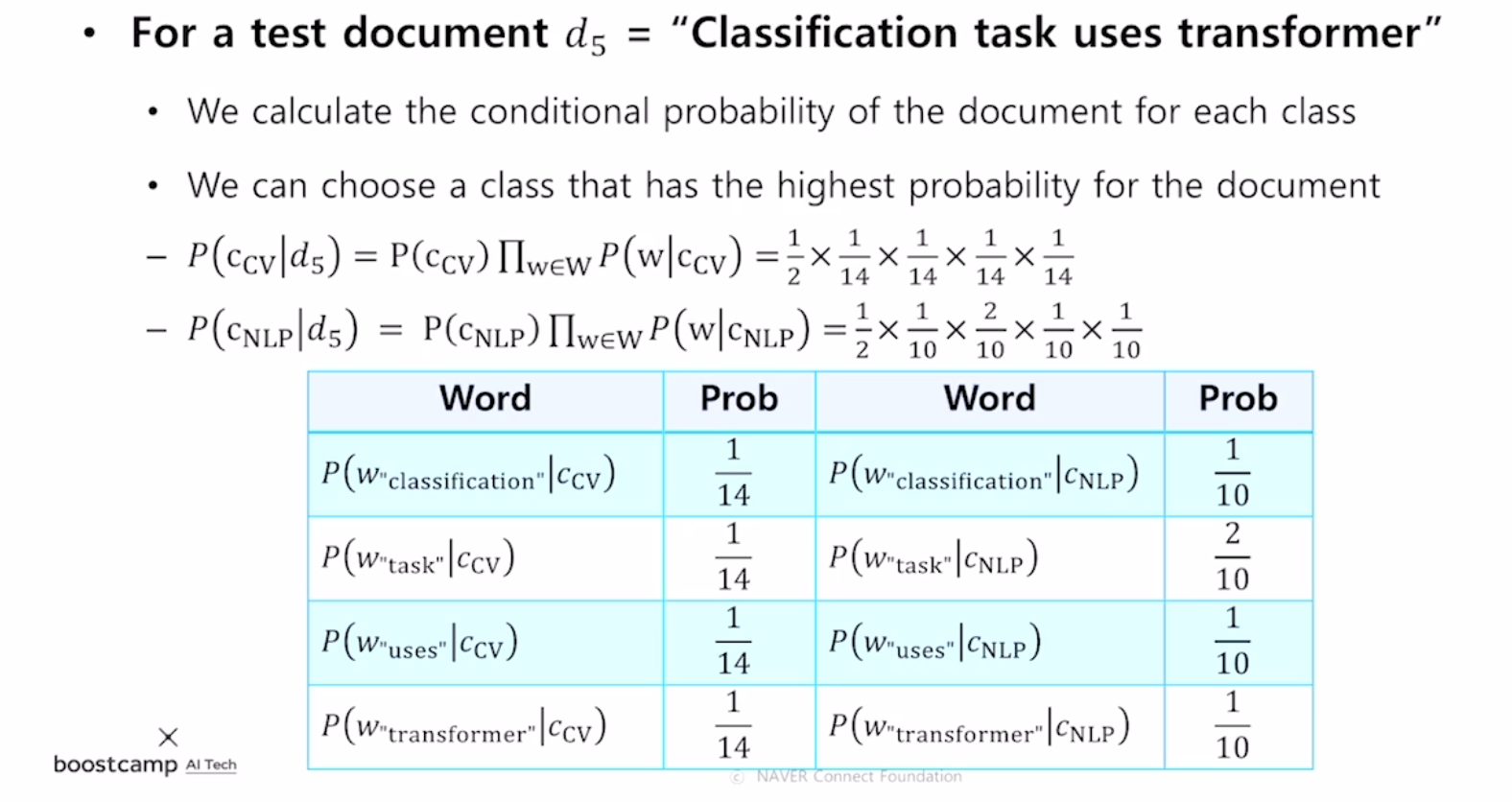
그리고 각 문서에서의 특정 단어가 나타날 확률은 다음의 표와 같을 때, 문서 d5가 주어졌을 때, 어느 클래스에 속할지 구하는 확률은 위에서 구한 공식에 대입하면 다음 그림과 같습니다.
d5가 cv클래스에 속할 확률 : cv 클래스의 문서가 뽑힐 확률 x P(w|c_cv) of words of w_d5
d5가 NLP클래스에 속할 확률 : NLP 클래스의 문서가 뽑힐 확률 x P(w|c_NLP) of words of w_d5
References
- RNN - 주재걸 교수님
Leave a comment