
Sequential Models - RNN
자연어 처리 분야에서 Recurrent Neural Network(RNN)가 무엇이고, Gradient Vanishing/Exploding의 문제를 보완한 Vanilla RNN을 발전시킨 LSTM을 알아보고, RNN의 Type을 알아봅니다.
Sequential Model - Naive sequence model
Sequential Data는 우리의 일상에서 언어나 주식 차트, 영상 등이 해당될 수 있습니다.
이미지 같은 고정된 차원의 데이터가 아닌 시간에 따라 데이터가 입력이 되는 시계열 데이터에 대해 동작하는 것이 Sequential Model이라고 할 수 있습니다.
예를 들어 현재 무슨 언어가 나올지 예측하는 모델을 생각해 볼 수 있습니다. 시간상으로 전에 나온 단어들로 미래의 단어를 예측한다던지..
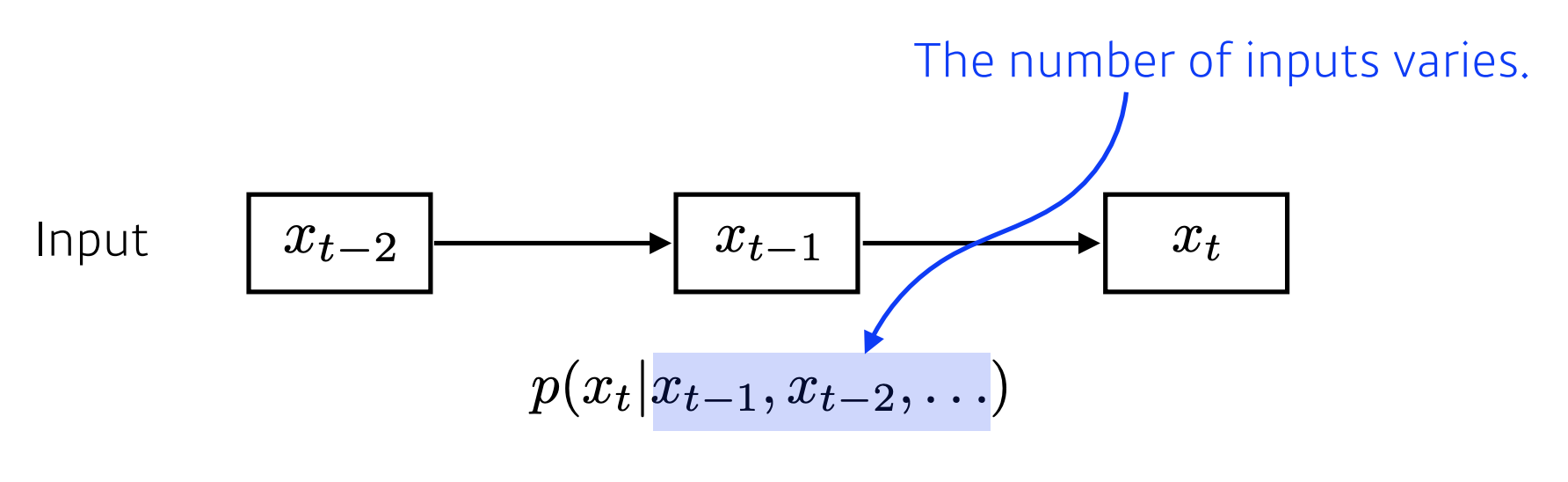
첫번째 단어가 입력이 되면, 두번째 단어는 첫번째 단어를 고려, 세번째 단어는 두번째, 첫번째 단어를 고려.. 반복
그럼 이 모델은 현재 단어를 예측하기 위해 고려해야 하는 데이터의 개수가 시간이 지남에 따라 계속 증가하게 됩니다.
Sequential Model - Auto regressive model
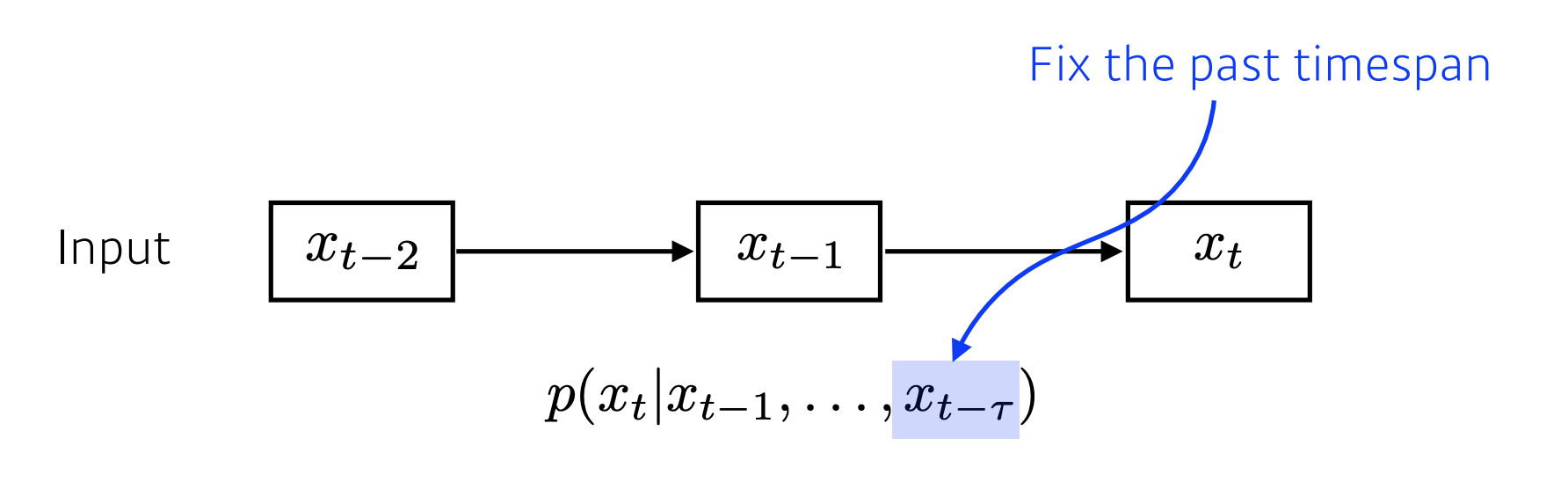
위의 모델은 현재를 예측할 때 과거의 데이터를 다 고려했다면, 이 방법은 fixed timespan을 두어 과거의 몇개만 고려하는 것입니다.
예를들어 과거에 대해 5개의 데이터만 보겠다하면 T의 값은 5가 됩니다. x_t = x_1 ~ x_5까지만 보겠다.
Markov model
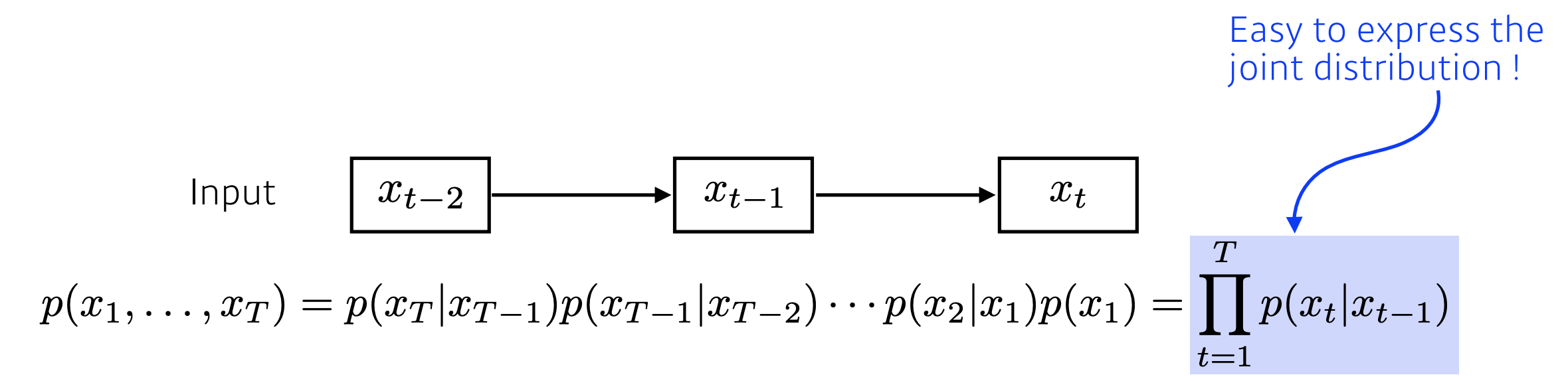
이 모델은 현재의 값은 직전 과거의 하나의 데이터에만 dependent 하다는 것을 가정으로 두게됩니다.
이 모델은 과거의 하나의 데이터만을 이용하기 때문에, 위의 모델에 비해 당연히 많은 과거의 정보를 이용할 수가 없게 됩니다.
Latent autoregressive model
처음 살펴본 두개의 모델의 가장 큰 단점은 과거의 방대한 데이터를 다 고려해야한다는 것입니다.
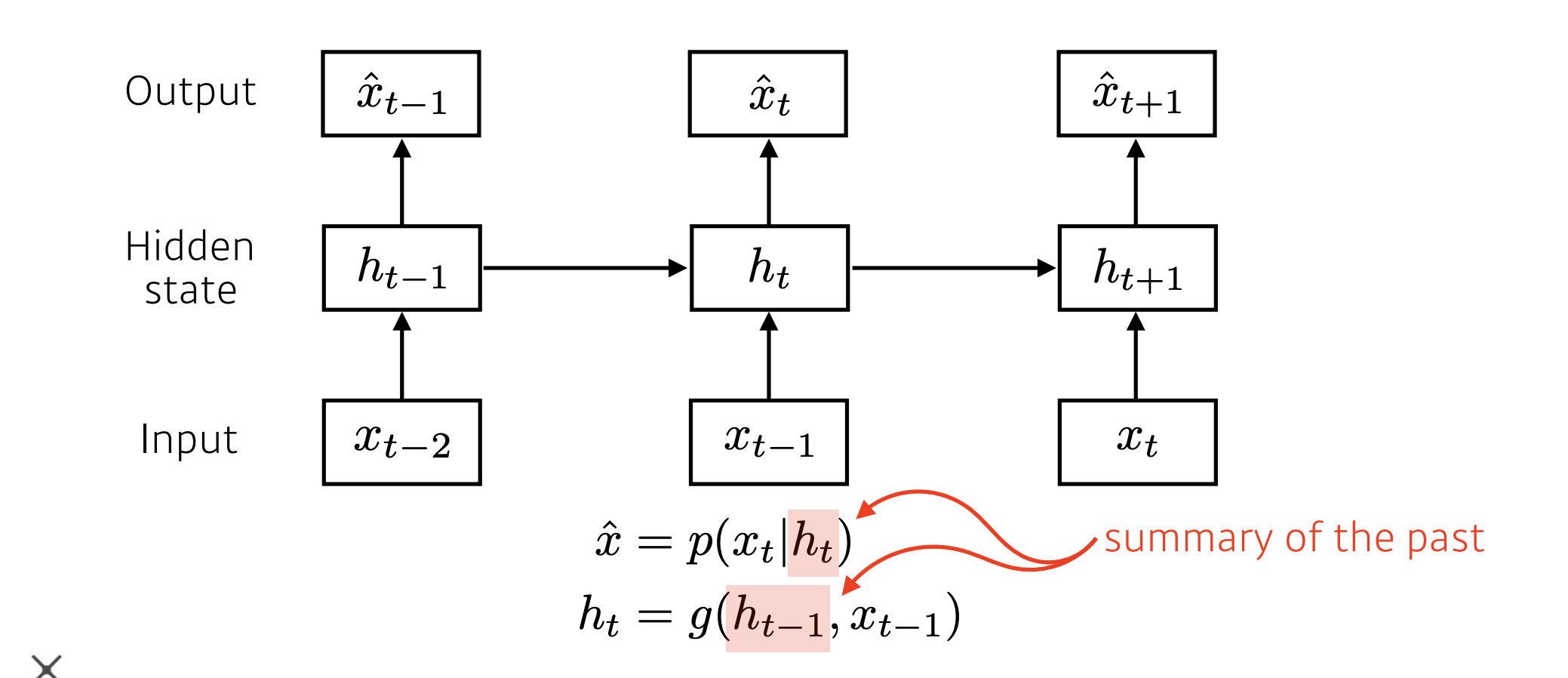
이 모델은 모델 중간에 Hidden state가 들어있는 모델입니다. 이 Hidden state가 하는 일은 과거 데이터의 정보를 summary 한다고 볼 수 있습니다.
그래서 다음의 타임스텝의 아웃풋은 현재의 인풋과 바로 이전의 Hidden state에 의존하여 작동할 수 있게 됩니다.
Recurrent Neural Network
위에서 설명한 여러가지 모델들을 가장 잘 표현한 것이 Recurrent Neural Network 라고 할 수 있습니다.
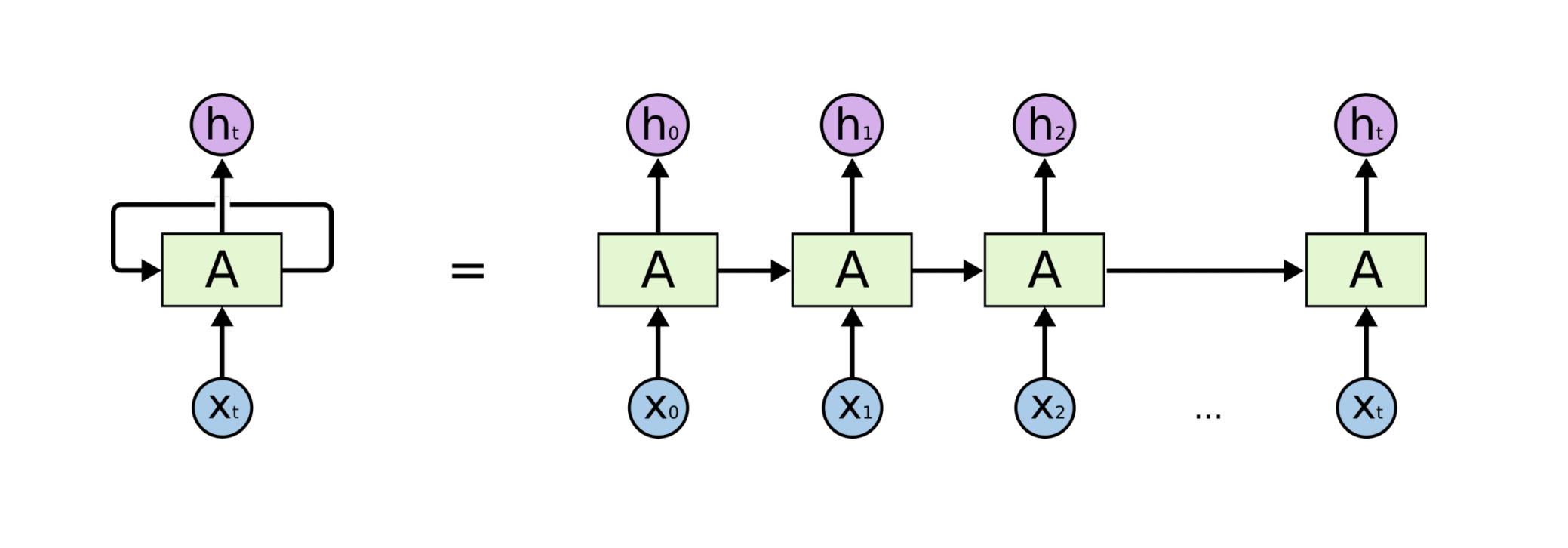
Recurrent Neural Network는 MLP와 다른 점이 있다면, 자기 자신을 돌아오는 구조가 하나 있다는 것입니다.
이런 구조에서 타임t에서의 h는 x_t에서만 dependent한 것이 아니라, t-1의 A로 표시된 Sell state에도 dependent 하게 됩니다.
밑의 그림에서 오른쪽 그림은 왼쪽에서의 그림을 시간순으로 쭉 나열한 것이 됩니다.
Short-term dependencies
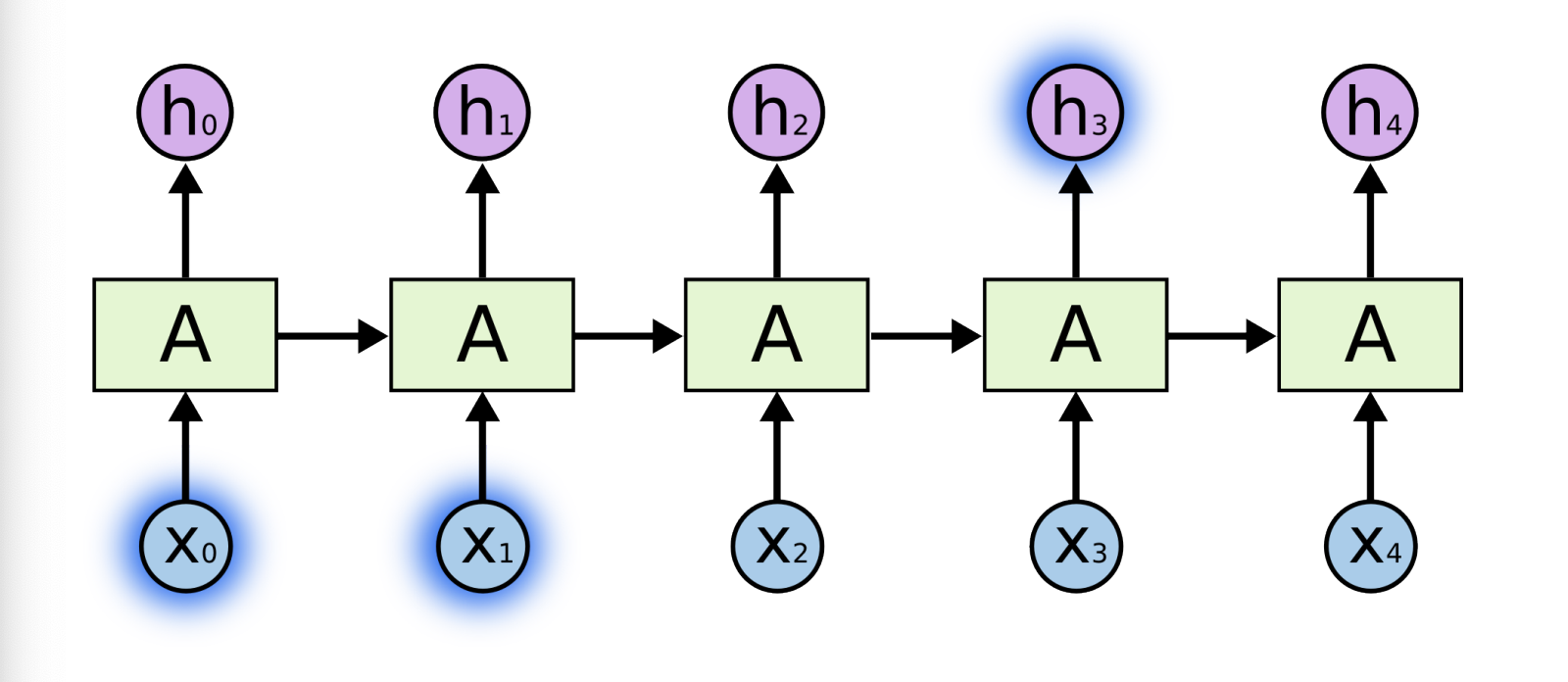
위에서 살펴본 RNN 구조에서의 가장 큰 단점이라고 한다면 Short-term dependencies을 들 수 있습니다.
과거의 모든 정보들이 다 취합이 되서 요약되고 미래에서 그것을 고려가 되어야하는데, RNN 자체는 하나의 fixed rule로 이 정보들을 계속 취합하기 때문에, 먼 과거에 있던 정보가 미래까지 살아남기 힘든 것을 의미합니다.
Short-term dependencies 즉, 현재에서 몇개의 전 과거의 데이터는 잘 고려가 되는데, 한 참 멀리 있는 정보를 고려하기 힘든것을 말하는 것입니다.
Long Short-term Memory
기존의 RNN 구조를 살펴보면, x가 A의 구조를 통과해서 h라는 아웃풋을 산출하고 h는 다시 다음번의 A구조로 들어가게 됩니다. 여기서 A구조에서는 weight와 계산이 되고, activation function과 계산이되게 됩니다.
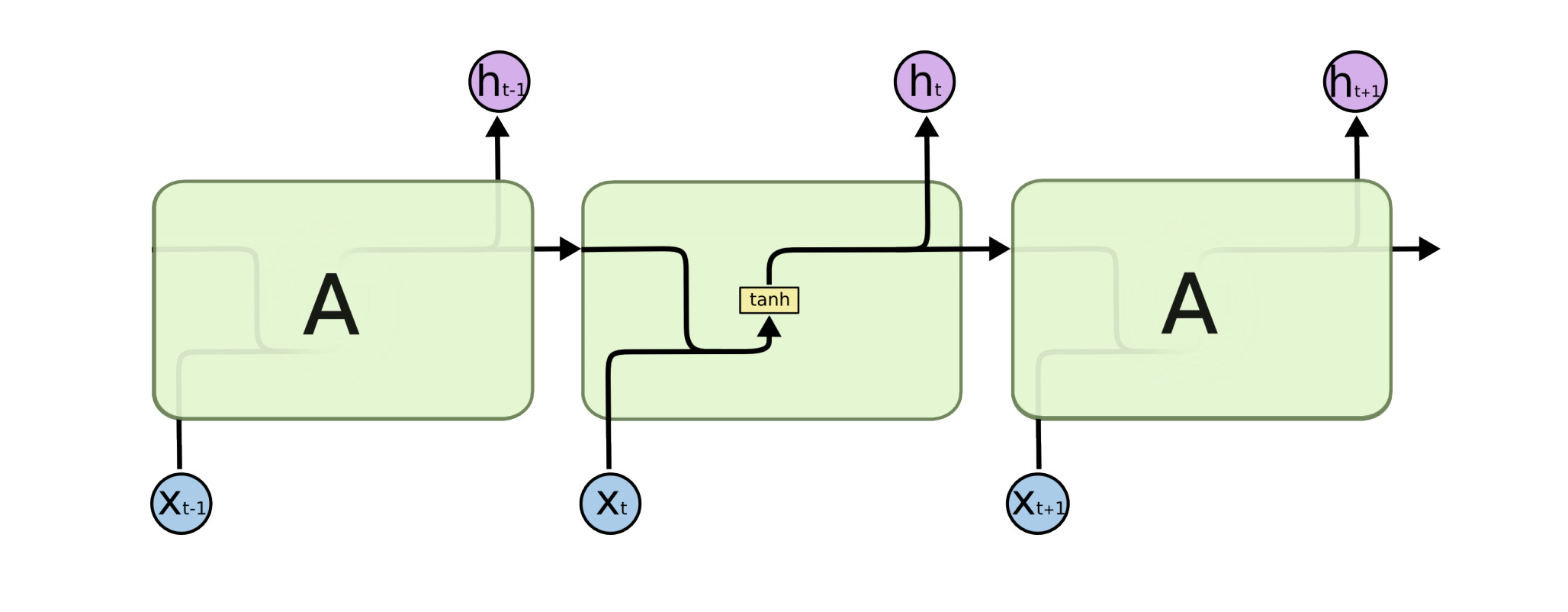
기존의 RNN을 개선한 Long Short-term Memory의 구조는 다음과 같습니다.
Long Short-term Memory의 각각의 컴포넌트가 어떻게 동작하고 이 구조가 왜 Short-term dependencies를 극복하는지 알아보겠습니다.
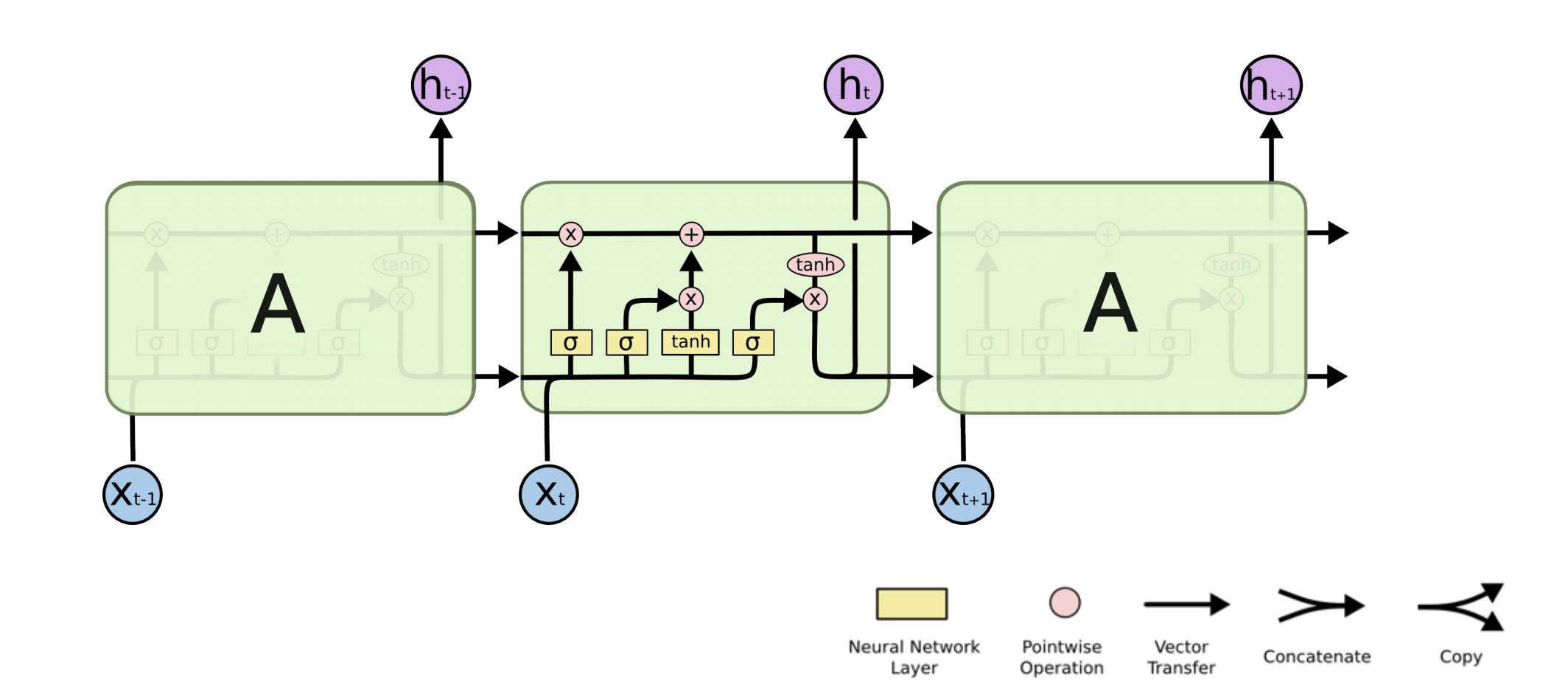
Long Short-term Memory의 구조를 세부적으로 묘사한 그림입니다.
x_t는 인풋으로써 언어 모델이라면 여러개의 단어(5000개의 단어)를 표현한 원-핫 벡터가 될 수도 있고, 워드 임베딩된 벡터로 표현될 수도 있습니다.
h_t는 hidden state이면서, output이 됩니다.
previous cell state는 0부터 t-1까지의 정보를 다 취합해서 summarize 해주는 정보가 됩니다.
previous hidden state는 위쪽으로 previous cell state 들어가기도 하지만 오른쪽으로 여러 연산의 입력으로도 들어가게 됩니다.
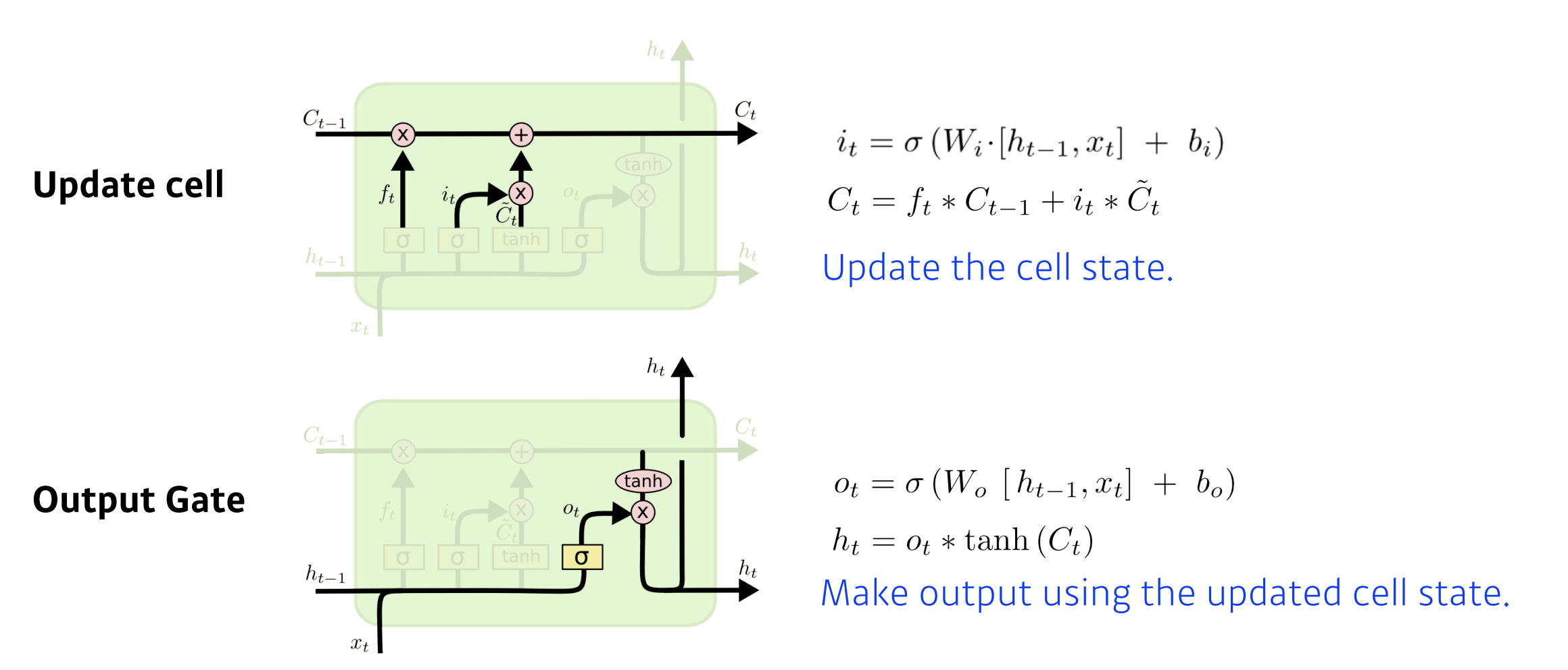
전체적으로 보면 들어오는 입력은 3개가 되고 나가는 출력도 3개가 됩니다. 출력 중 2개는 다음번 입력으로 들어가고, 나머지 하나는 실제 아웃풋이 됩니다.
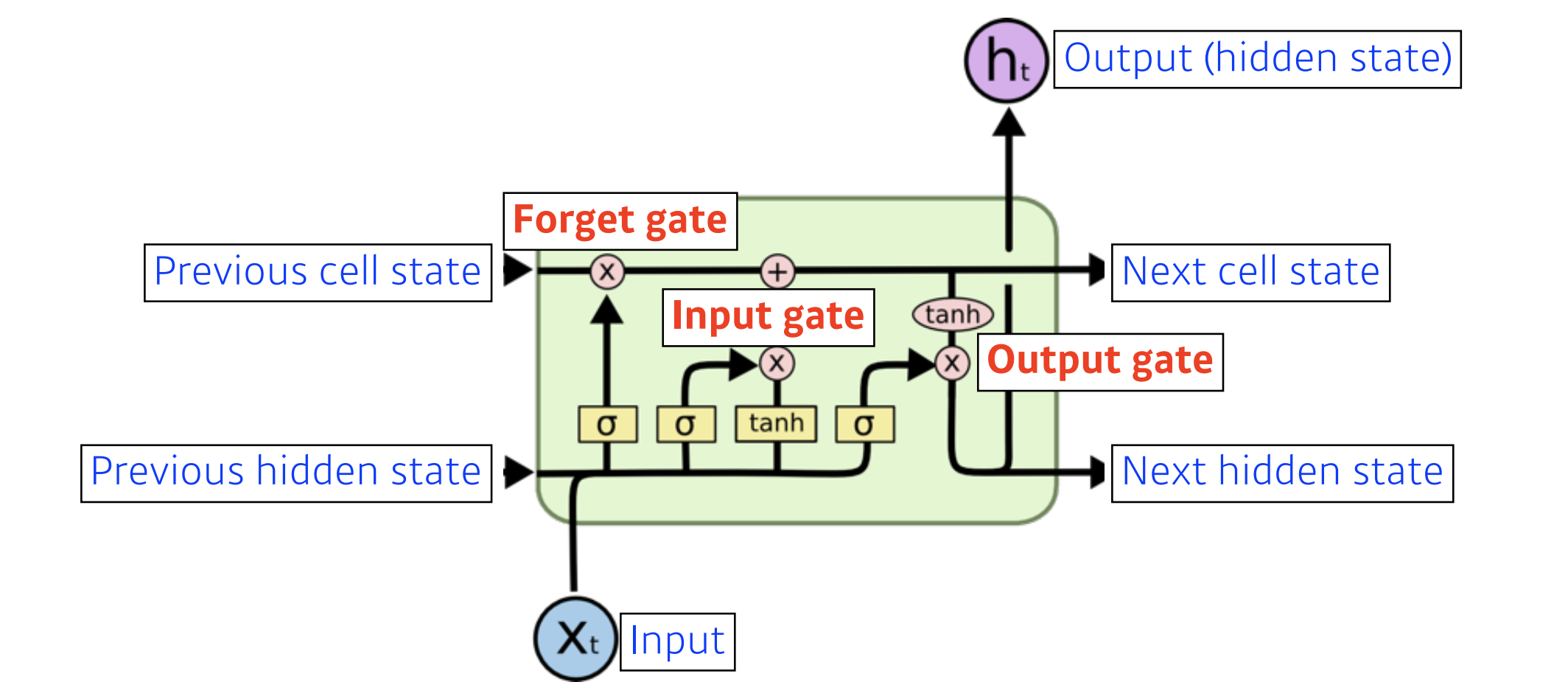
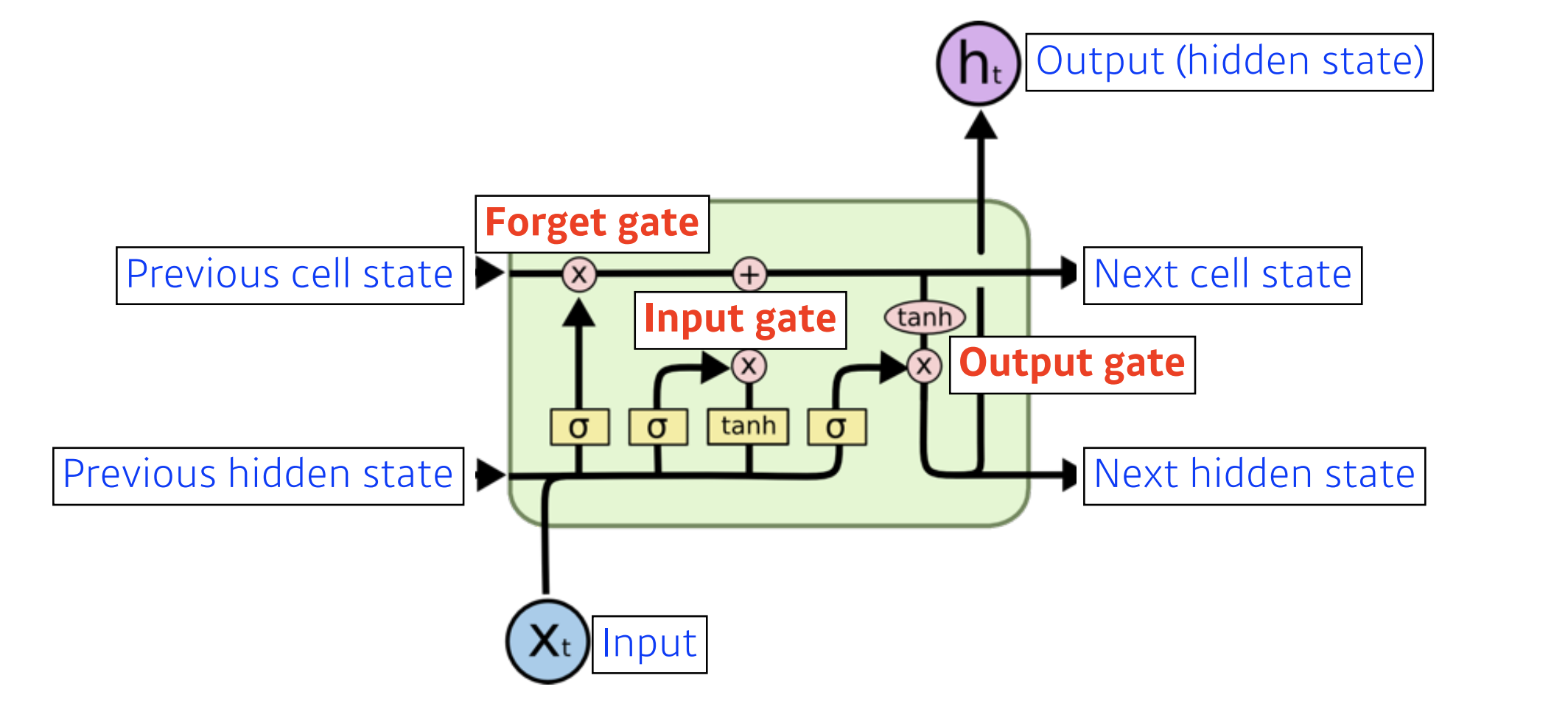
Long Short-term Memory은 총 4개의 gate로 이루어져 있습니다.
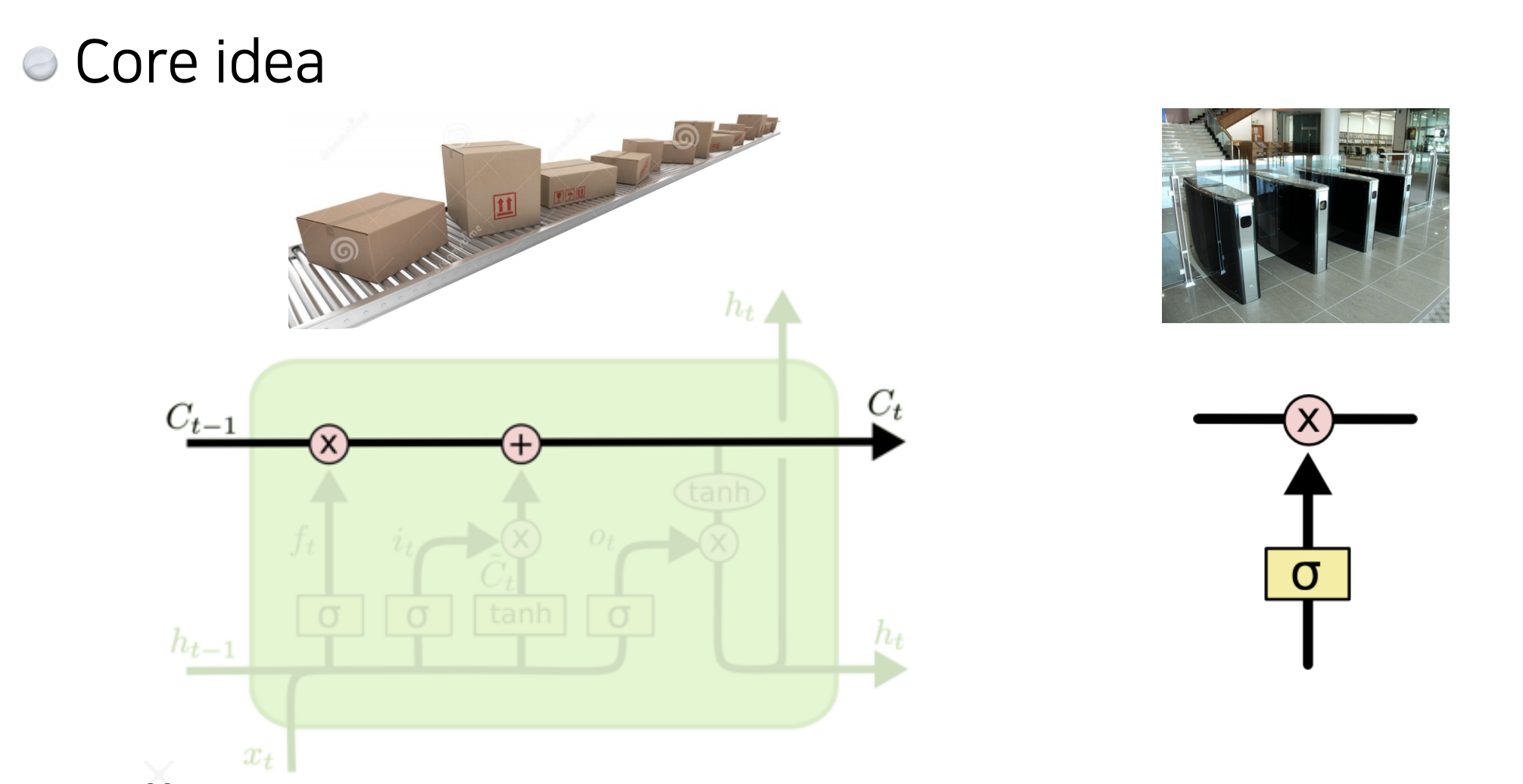
그림에서 검은 선이 바로 cell state이고, C_0부터 C_t 까지 들어온 정보를 요약하게 됩니다.
타임스탬프 t마다 컨베이어 벨트에서 처럼 물건(정보)이 올라오고, 그 정보들을 잘 조작해서, 어떤 것이 유용하고 어떤 것이 유용하지 않은지 정해서 다음번 셀로 이 정보들을 넘겨주는 역할을 하게 됩니다.
정보들을 잘 조작해서, 어떤 것이 유용하고 어떤 것이 유용하지 않은지 정해서 올리는 역할은 gate가 하게 됩니다.
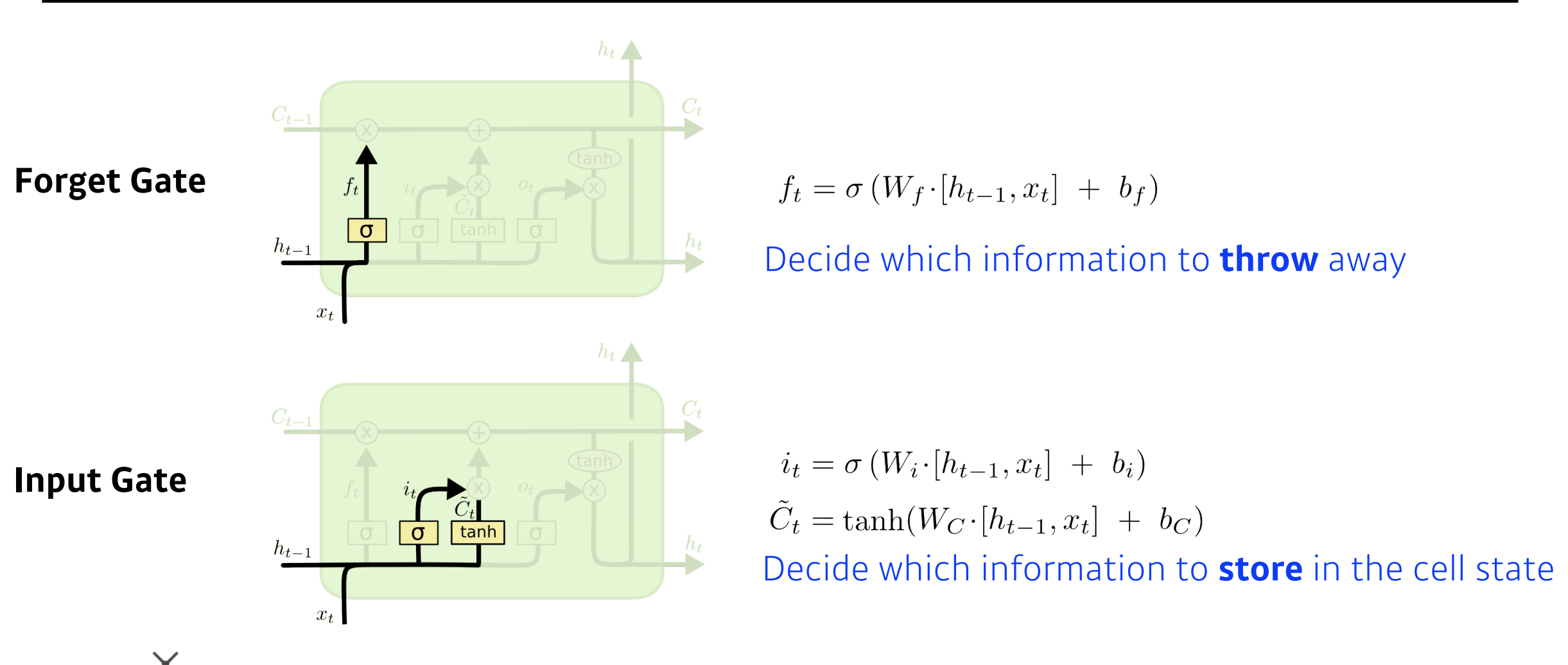
Forget gate는 어떤 정보를 버릴지 정하는 역할을 합니다.
Forget gate에는 현재의 입력 x_t와 이전의 hidden state value인 h_t-1이 들어가서 f_t라는 숫자를 얻어내게 됩니다. 시그모이드를 통과하기 때문에 항상 f_t는 0에서 1사이 값을 갖게 됩니다.
f_t는 이전 cell state에서 나온 정보들 중에 어떤 것을 버리고, 어떤것을 살릴지 정해주게 됩니다.
Input gate는 어떤 정보를 cell state에 저장할지(올릴지) 정하는 역할을 합니다.
현재에 어떤 입력이 들어왔는데, 이것을 무작정 cell state에 올리는 것이 아닌, 이 정보중에 어떤 정보를 올릴지 정하게 됩니다.
i_t는 어떤 정보를 cell state에 올릴지 또는 저장할지 정하게 됩니다. 이전의 hidden state value와 현재의 입력을 가지고 만들어 지게 됩니다.
그렇다면 우리가 실제로 올릴 정보를 알아야합니다.
C_t~가 이 역할을 하게 됩니다.
update gate는 이전까지 summarize 되어있던 cell state와 올릴지 또는 저장할지 정하는 i_t 그리고 C_t~를 가지고 cell state에 update하는 역할을 합니다.
이전 cell state인 C_t-1과 f_t 만큼을 곱해서 C_t-1에서 어떤 정보를 버리게 되고 나오는 값 A, C_t~와 i_t만큼을 곱해서 어느 값을 올릴지를 정해서 만들어진 값 B, 이 두 값을 combine해서 다음 cell state인 C_t으로 업데이트 하는 역할을 합니다.
Out state는 어떤 값을 밖으로 내보낼지 결정하는 역할을 합니다.
o_t는 어떤 값을 내보낼지 정하는 역할을 하게 되고 이를 thanh를 통과한 C_t인 updated cell state와 Element wise multiplication을 해서 결정적으로 h_t가 만들어 지게 됩니다.
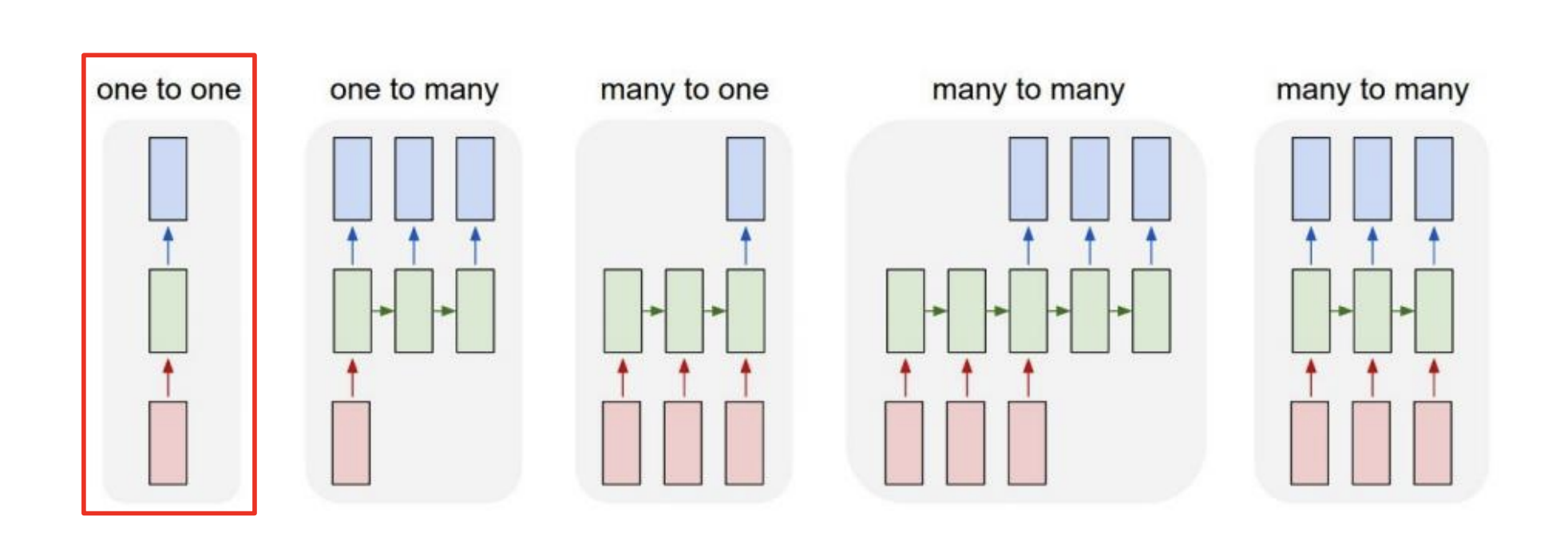
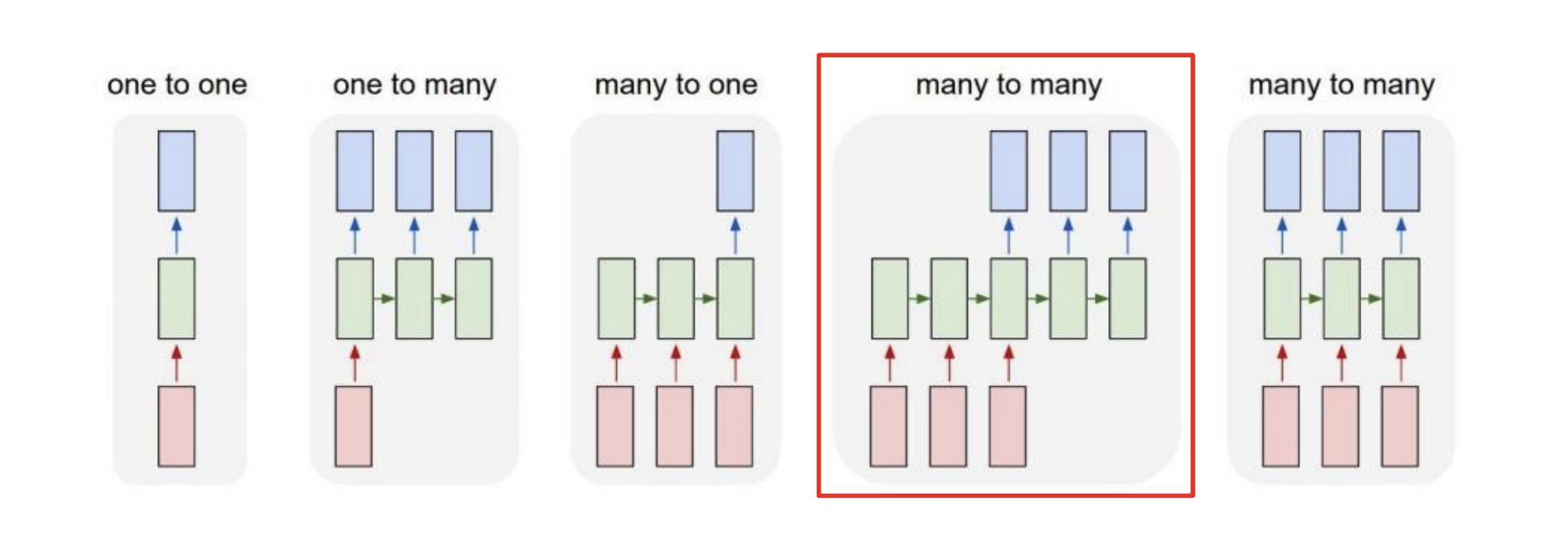
Types Of RNNs
다루고자 하는 데이터와 문제에 따라 RNN을 여러 형태로 하여 구성할 수 있습니다.
- one-to-one
- one-to-many
- many-to-one
- many-to-many
One-to-one
입력과 출력의 타임스탭이 단 하나인 스탠다드한 모델 구조를 말합니다.
모델은 입력 벡터를 받아 가중치를 이용해 입력 벡터를 선형변환과 필요하다면 비선형 함수를 적용하고, 출력 벡터를 산출한다는 의미가 됩니다.
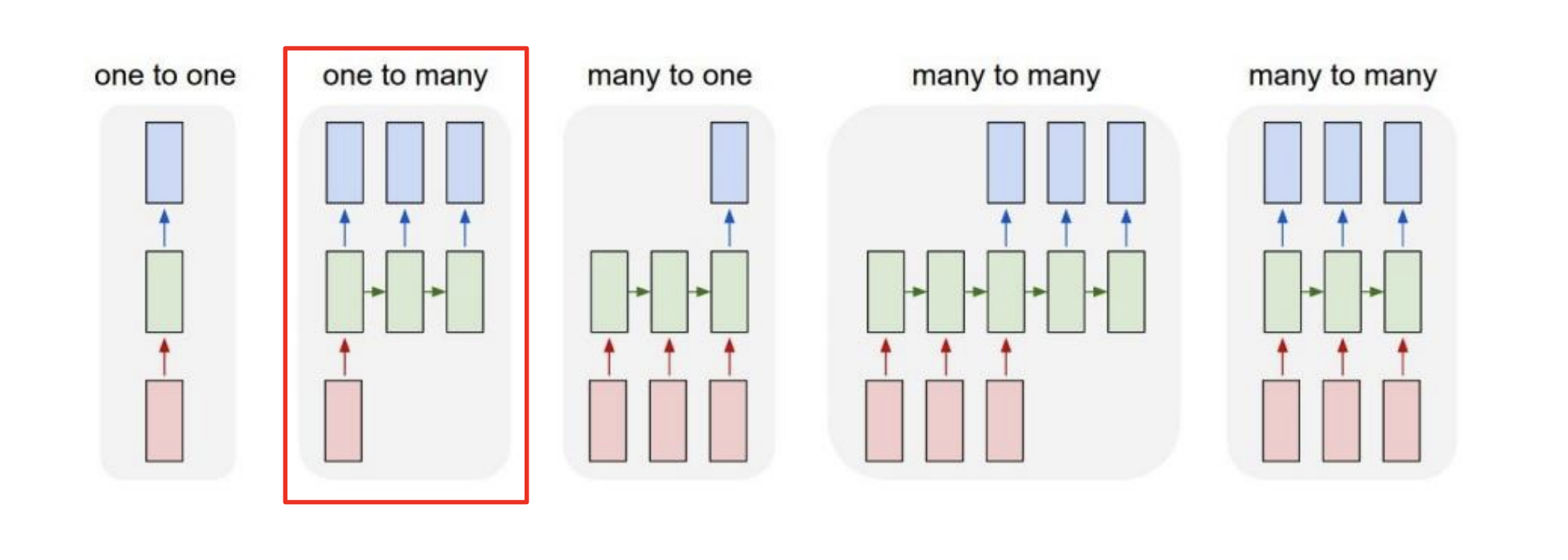
One-to-many
입력이 하나의 타임스탭으로 이루어지고, 출력은 여러 타임스탭으로 이루어진 모델 구조를 말합니다.
대표적으로 Image Captioning이 이에 해당할 수 있습니다. 입력으로는 하나의 이미지를 받고, 이 이미지에 대한 설명으로 각 타임스탭마다 하나의 단어를 산출한다는 점을 들 수 있습니다.
매 타입스탭마다 모델로 입력이 주어져야 하지만, 밑의 사진처럼 따로 주어질 입력이 없는 경우 원래의 입력 사이즈와 같고 값이 0으로 채워진 벡터나 행렬을 입력으로 주게 됩니다.
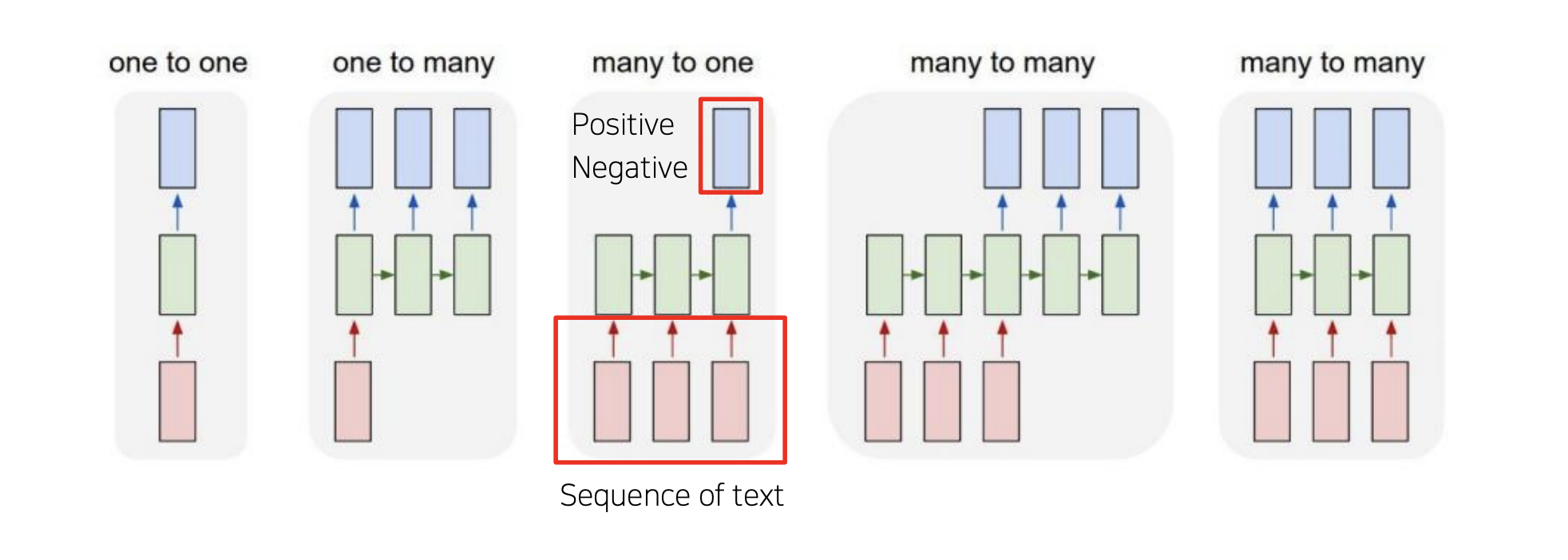
Many-to-one
입력이 여러개의 타임스탭으로 이루어지고, 출력은 하나의 타임스탭으로 이루어진 모델을 말합니다.
대표적으로 여러개의 입력을 받아 종합적으로 이 입력들의 감정을 분류하는 Sentiment Classification을 예로 들 수 있습니다.
Many-to-many
입력과 출력 모두 여러개의 타임스탭으로 이루어진 시퀀스한 모델을 말합니다.
대표적으로 입력 단에서 특정 어느 나라 말을 끝까지 시간순으로 읽은 후, 출력단에서 순차적으로 다른 나라말로 번역(예측)이 되는, 기계독해 - Machine Translation을 예로 들 수 있습니다.
References
- RNN - 주재걸, 최성준 교수님
Leave a comment