
Sequence to Sequence
Sequence를 Encoding과 Decoding 할 수 있는 sequence to sequence에 대해 알아봅니다.
Sequence to sequence는 encoder와 decoder로 이루어져 있는 framework으로 대표적인 자연어 처리 architecture 중 하나입니다.
Encoder-decoder architecture
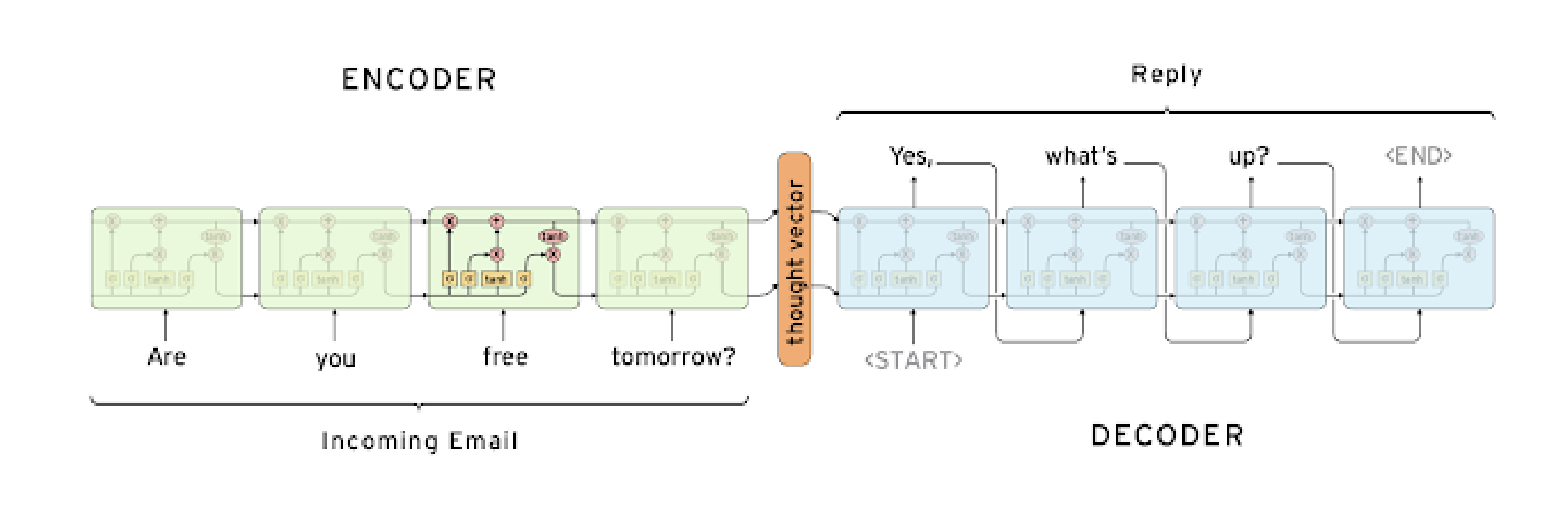
Sequence to Sequence 모델은 여러개의 입력 단어 시퀀스를 받아 처리하는 Encoder, 출력 단어를 순차적으로 생성하는 Decoder로 구성됩니다.
각각의 모듈은 서로 파라미터를 공유하지 않는 독립된 RNN 모듈이라고 생각할 수 있습니다.
그림에서는 RNN 모델을 LSTM 모듈로서 채용한 것을 알 수 있습니다.
Sequence to Sequence의 Encoder에서 입력 단어의 마지막 까지 읽어들인 후, Encoder에서 나온 제일 마지막 hidden state vector가 Decoder로 제일 처음 h0 벡터로서 입력으로 들어가게 됩니다.
h0는 입력 단어들을 잘 요약 정리한 정보라고 할 수 있고, 이는 출력단에서 순차적으로 처리가 되어 대응 되는 다음 단어를 생성하는데 사용될 수 있습니다.
Start 토큰은 실질적으로 예측하고자 하는 결과 단어를 만들기 위한 제일 처음 넣어주는 인풋값으로서 사용하게 됩니다.
End 토큰은 Decoder에서 문장이 끝나는 시점을 의미하고, 이 토큰이 생성되면 디코더의 실행은 멈추게 됩니다.
Seq2Seq Model with Attention
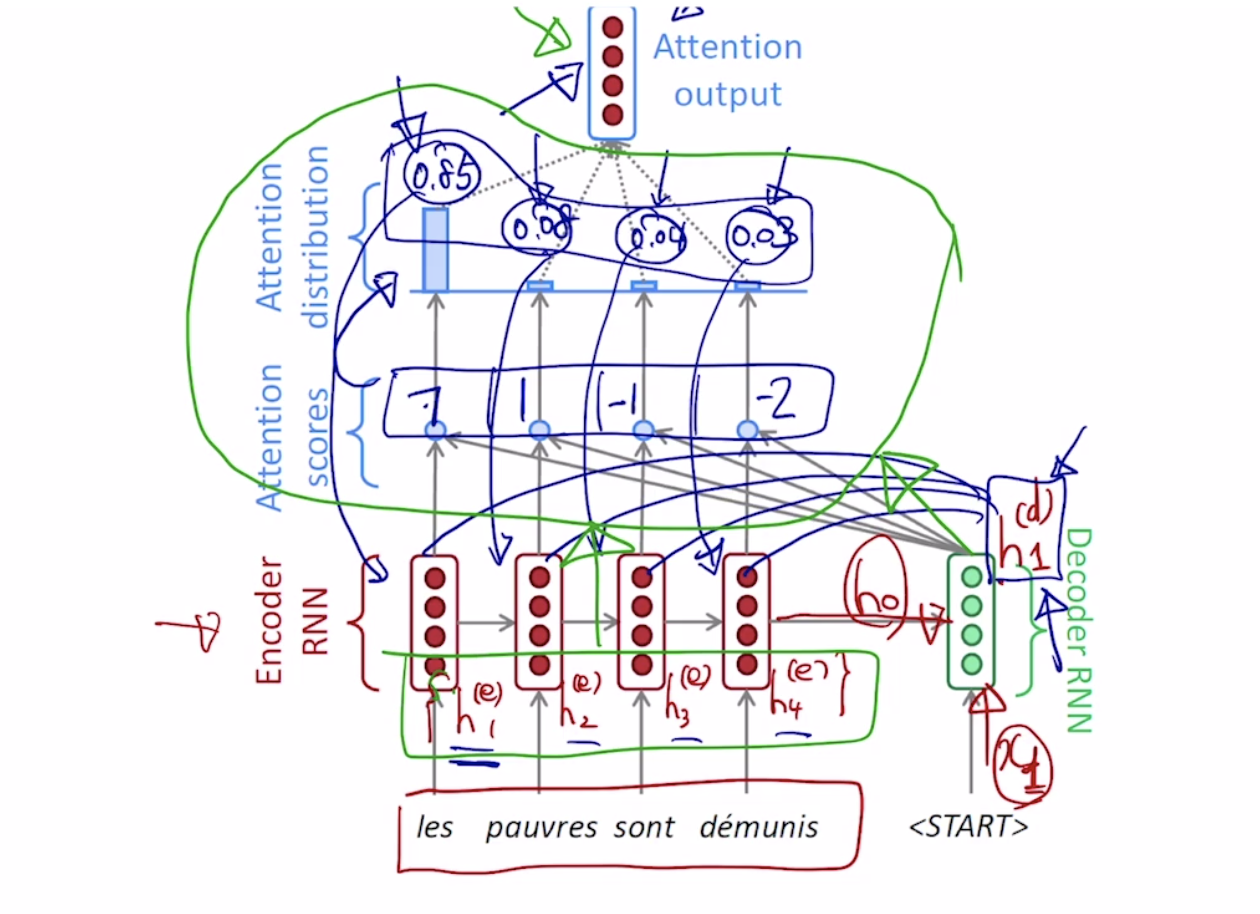
기존에는 인코더의 마지막 hidden state 벡터의 입력만 디코더에 넣어줘서 결과를 순차적으로 생성했다면, Attention을 적용한 경우에는, 인코더에서 각각의 타임스탭마다 만들어진 중간 노드들의 hidden state vector들을 디코더의 매 타임 스탭마다 하나의 정보로서 같이 활용하게 됩니다.
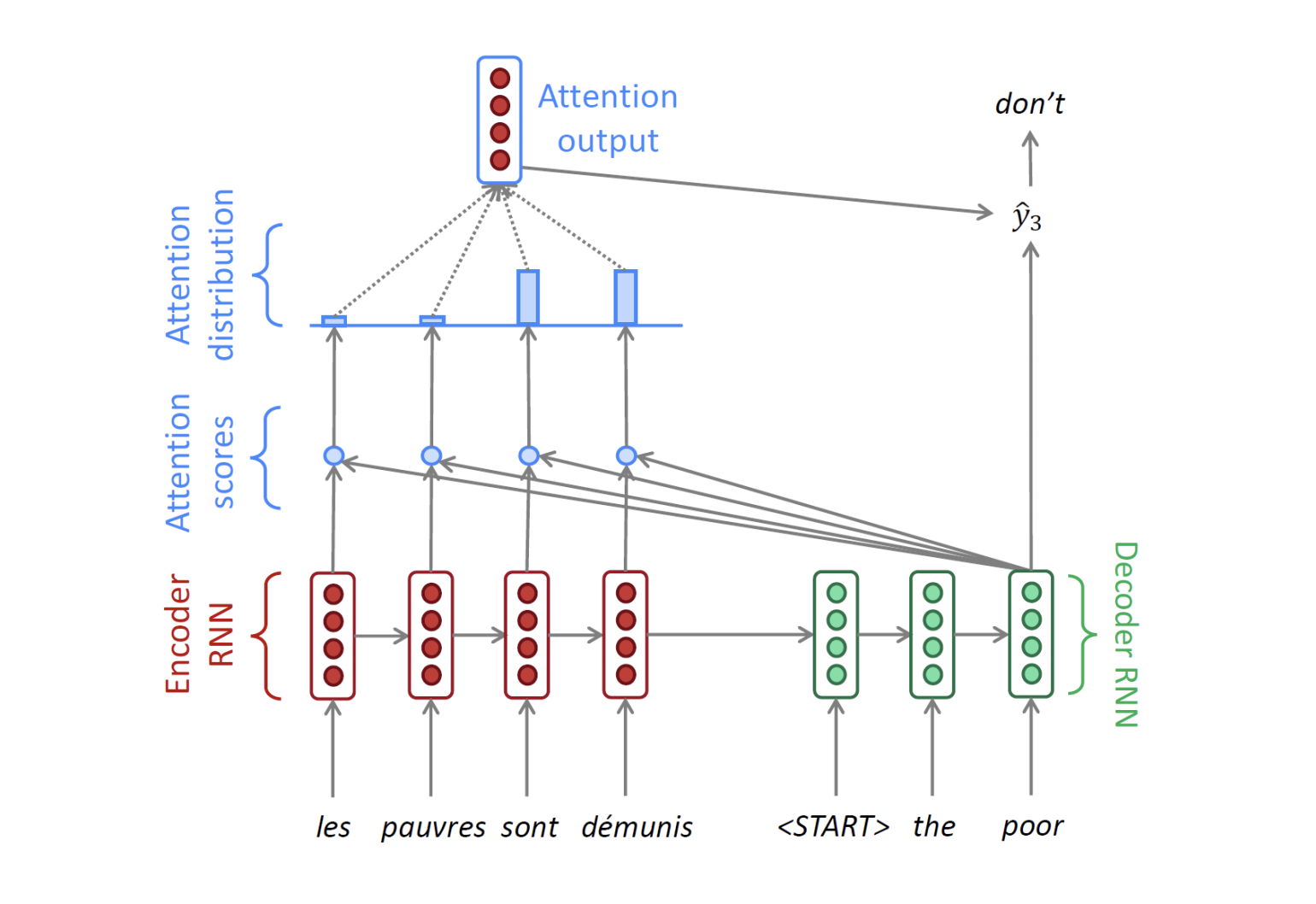
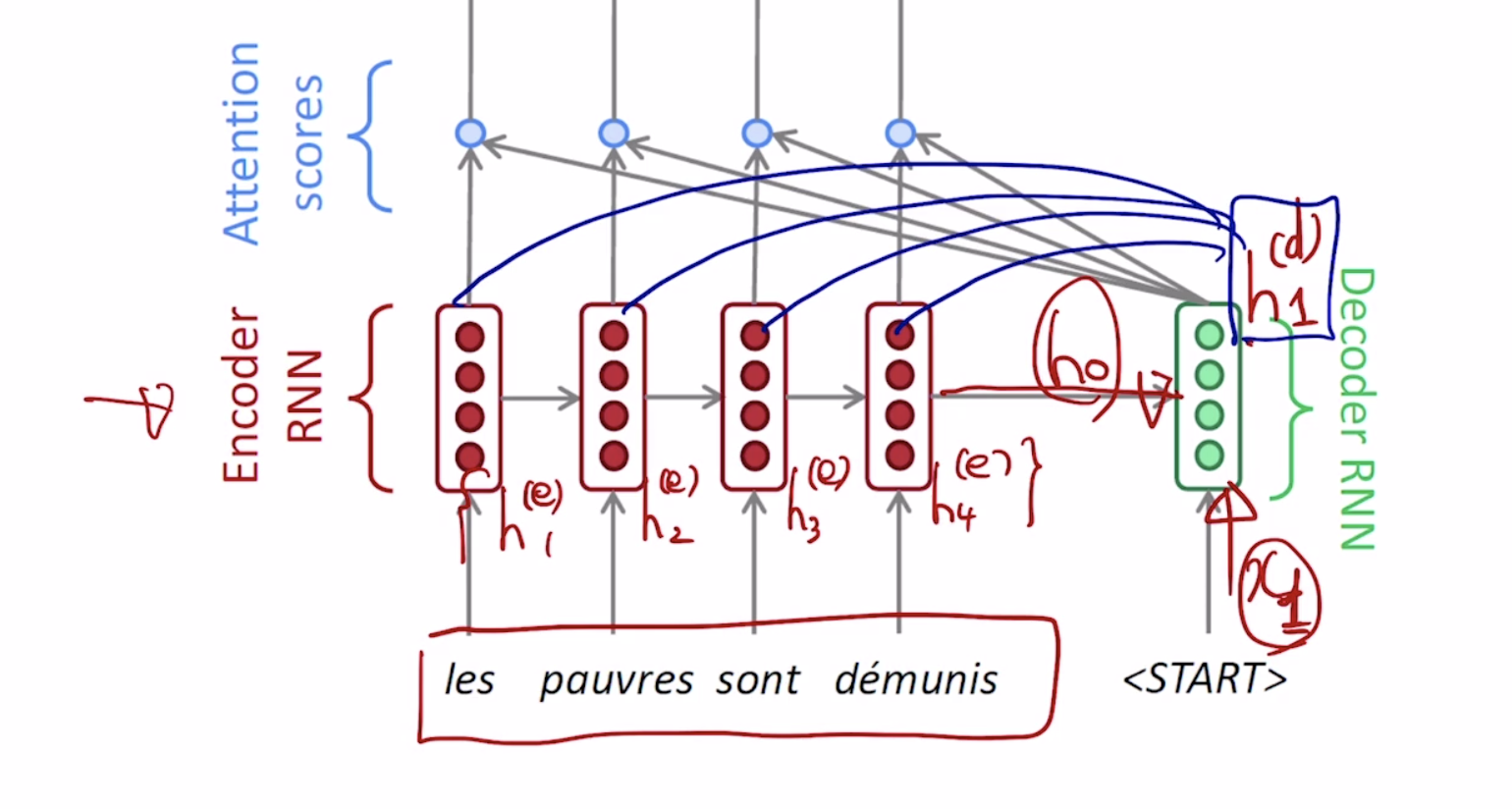
인코더에서 만들어진 마지막 hidden state vector = h0와 start 토큰이 디코더를 거쳐 h1 state vector를 만들게 되는데 이는 인코더 단의 각각의 매 타임 스탭마다 만들어진 h1 ~ h4와 각각 내적의 연산을 수행하게 됩니다.
이 내적 연산의 결과값의 의미는 h1 state vector와 각각의 인코더 hidden state vector간의 내적에 기반한 유사도라고 할 수 있습니다.
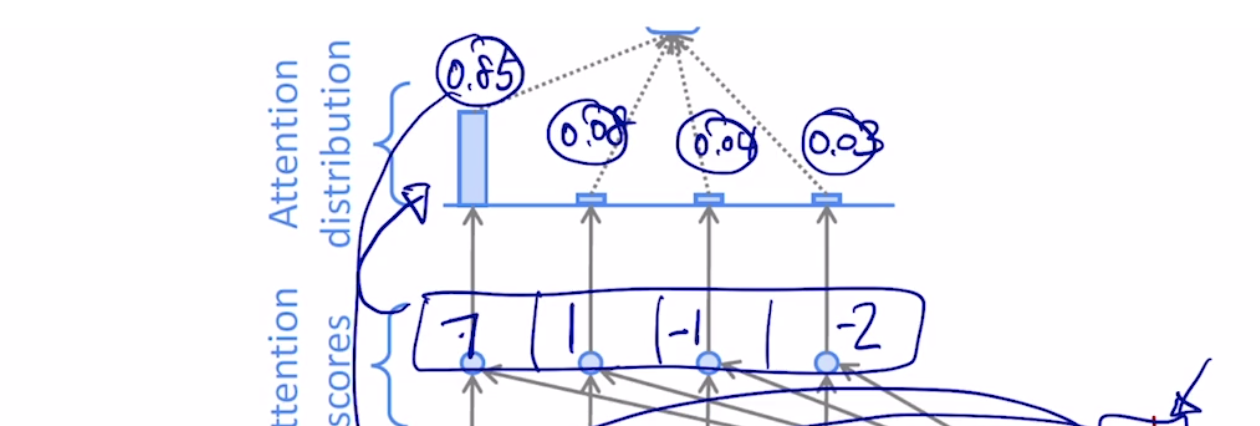
우리는 이 값들을 다시 소프트맥스 층에 적용하여, 각각의 인코더 hidden state vector와의 대응되는 확률 값으로 해석할 수 있습니다.
이 각각의 값들은, 각각의 인코더 hidden state vector로의 부여되는 가중치로서 사용이 되고, 이 4개의 값들을 가중평균을 내어 다시 종합된 하나의 인코딩 vector를 생성할 수 있게 됩니다. 이를 context vector 라고도 부릅니다.
예시로든 사진에서는 0.85의 값이 제일 높은데 이는, 인코더의 첫번째 타임스탭의 단어를 제일 높은 확률로 필요로 한다는 의미가 됩니다.
밑의 그림에서 녹색 원 안에의 부분을 우리는 Attention 모듈이라고 부르게 되고, 입력으로 인코더 단에서의 각각의 hidden state vector와 디코더 단에서의 hidden state vector가 들어가게 되고, Attention 모듈의 출력으로는 인코더 단에서의 각각의 hidden state vector의 가중 평균이 되는 context vector가 됩니다.
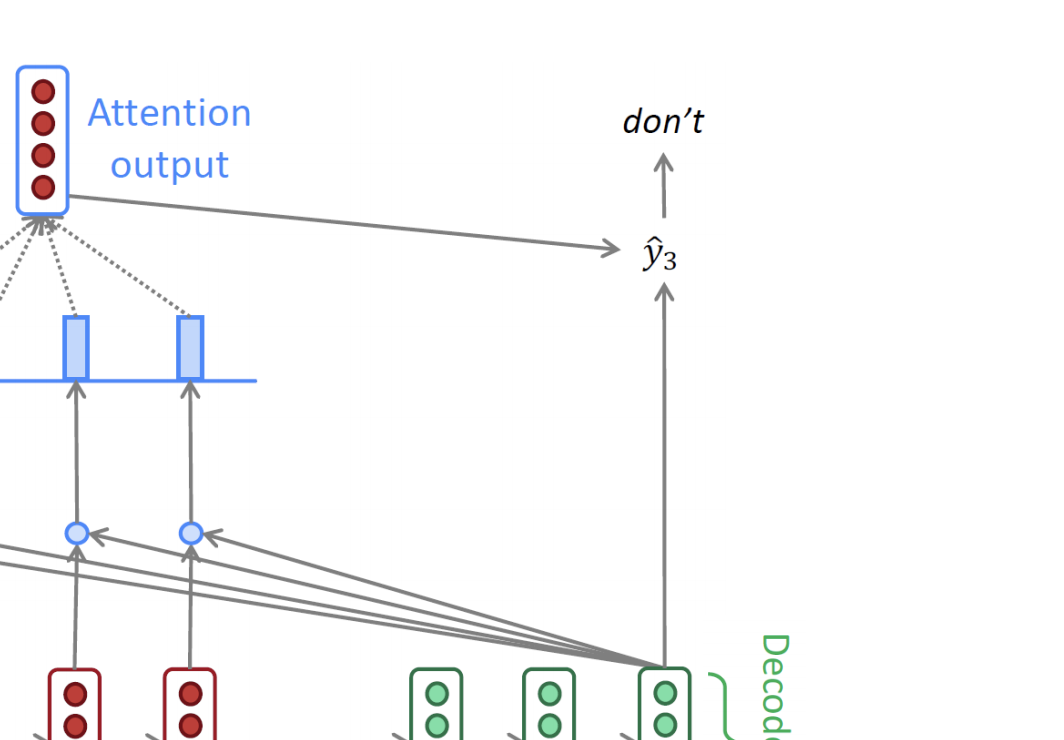
이렇게 만들어진 context vector는 앞서 만들어진 디코더 단의 hidden state vector와 concat이 되어서 그림에서는 y3 아웃풋을 만들게 되고, 이는 다음 타임 스탭으로의 입력으로 들어가게 됩니다.
디코더 단에서 y6인 money를 예측하는 타임 스탭에서의 그림은 다음과 같습니다.
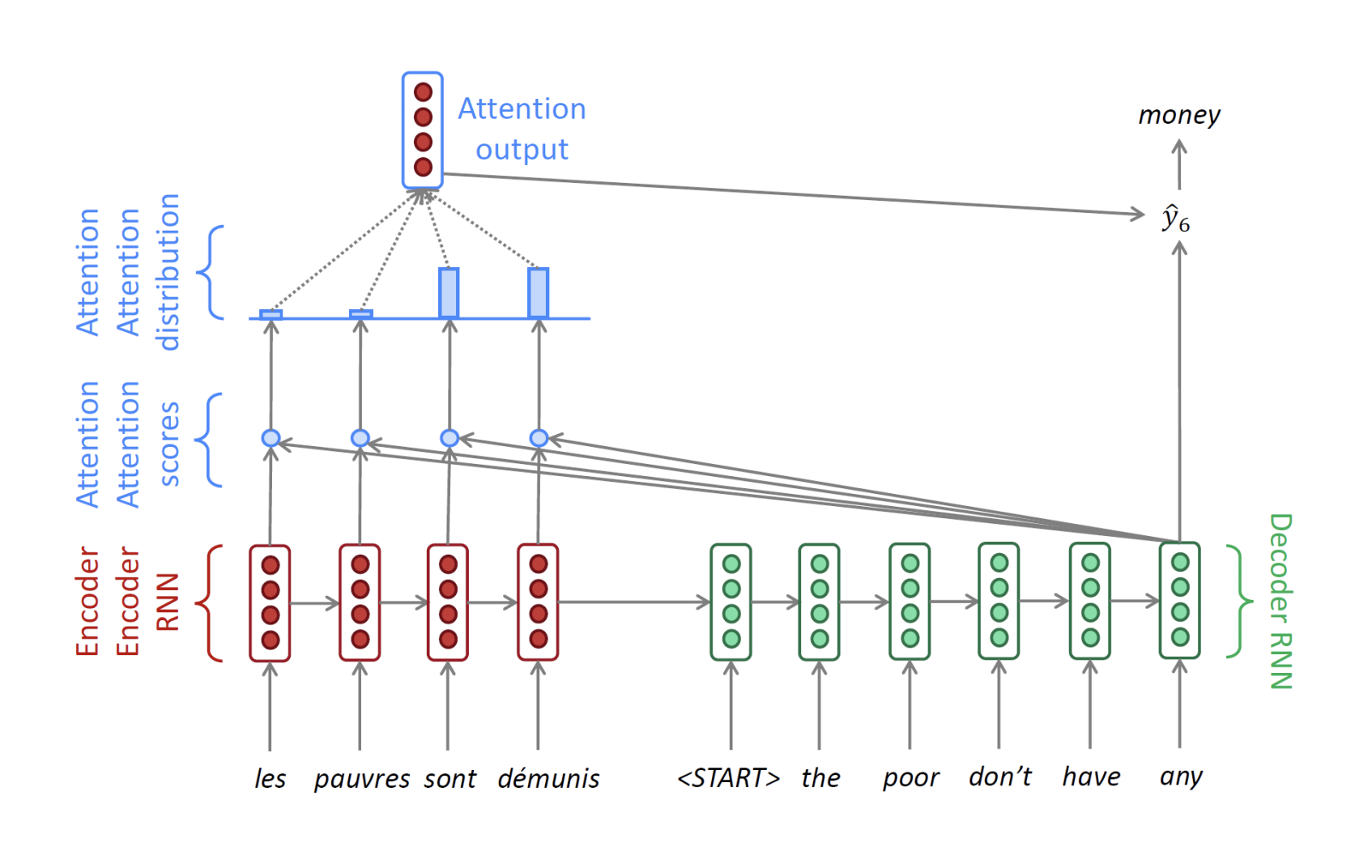
이렇게 디코더 단에서 매 타임 스탭마다 단어를 예측하는데에 있어서 각각의 인코더 hidden state vector가 쓰이게 되고 매번 다른 가중치가 적용된 가중평균된 context vector를 생성하게 되고, context vector가 매 타임 스탭마다 생성되고 아웃풋에 직접적인 입력의 일부로서 사용이 되어 그 해당 타임 스탭에서의 보다 좀 더 정확한 예측이 가능하도록 하게 만듭니다.
이를 End of sentence를 의미하는 END 토큰이 나올 때 까지 반복을 하게 됩니다.
References
- RNN - 주재걸, 최성준 교수님
Leave a comment